|
本人从事搜索引擎相关的工作已有十一年,今天与大家一起谈谈搜索引擎核心算法之:自然语言和布尔搜索。论述引出了如下结论:搜索爬虫和搜索引擎使用某种启发式方法给网页排名,并返回结果。爬虫观察模式,以确定某网页的内容,搜索引擎在搜索查询中查找模式,并与爬虫识别的模式进行比较,并返回结果。 这个理论的复杂性在于,我们使用的是活跃的、不断成长、不断演变的语言,这意味着语言的使用模式也在不断变化。为了跟上这种变化,搜索引擎也必须是活跃的、不断成长、不断演变的,所以在理解如何针对搜索引擎定位阿站时,启发式方法是一个非常重要的概念。理解它的最简单方法是比较过去和现在的搜索行为,确定搜索是如何演变的。 开始时使用布尔搜索 今天,人们的搜索方式与搜索引擎刚刚问世时的搜索方式完全不同。记得以前提过 Archie、Gopher、Jughead和verojnuca 这些早期的索引和搜索程序的能力是相当有限的,要在索引中查找信息,必须对索引非常了解。实际上,使用Archie和Gopher时,必须知道所要查找的文档或文件的确切位置。
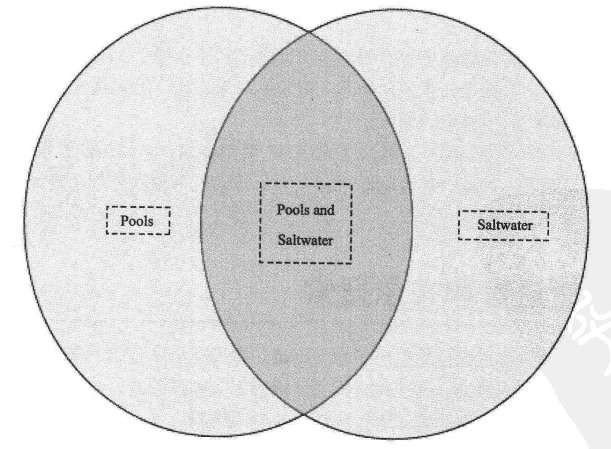
有了Jughead和Veronica后,就可以实际搜索信息了:但那时,搜索仍是非常基本的。当搜索最终变为可能时,如何查找文件是有一些严苛的规则的。在搜索引擎的早期,还没有今天非常普遍的自然语言搜索。 用户必须指定他们要搜索“这个短语”,而不是搜索“那个短语”,或者精确搜索某个短语.输入靠尔逻辑——在索引中查找正确的文件或文档所需的方法。布尔逻辑基于GeorgeBoole在19世纪中叶提出的逻辑代数系统。 实际上,布尔逻辑就是把数据分解为集合,直到数据集合非常小,满足初始查询提出的要求为止。例如,在搜索时,网络上可能有1000个网页有关“pools”,有1000个网页有关“saltwater”,如果搜索“saltwater pools”,就会返回所有2000个阿页。这实在太多了。但合并这两个术语,仅查找既包含“saltwater”、又包含“pools”的网页,则只返同原来2000个阿页中的一小部分,如图5—1所示。 为了使这个例子更进一步,可以添加一个限制符,例如“not chlorine”,以缩小数据集合。添加这个限制符时,会去除另外部分数据,满足“pools,saltwater. but not chlorine”查询的选项就更少了,如 这个例子演示了布尔搜索中使用的3个运算符:与、或、非。布尔逻辑基于逻辑代数系统,所以这些运算符都可以用一个符号表示: ·与:+ ·非; ·或:默认运算符,返回包含任意一个单词的所有页面,而不管它们的接近程度如何。该运算符用单词之间的空格表示。 刚开始时有2000个网页,但使用布尔逻辑运算符来分解数据集合,就大大减小了搜索范围。现在找到需要的内容的可能性更大,且查找速度更快。 在互联网搜索的早期.布尔逻辑帮助用户定位需要的文件和文档。从启发式方法的角度来看,布尔逻辑为搜索提供了完美的问题解决能力。但技术会逐渐成熟起来…… 小站(BET365) (责任编辑:admin) |