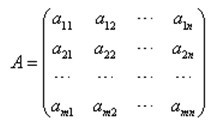|
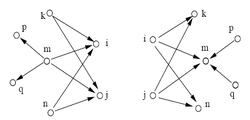
看过这篇文章后,你或许可以明白以下两件事儿: 1、一个单页面网站,为啥页面上都是出链,被指向的链接也很少,但是却有很好的排名; 2、网站页面上是不是没有出链(指向外部的)才是最好的? 看完上述,有兴趣没?好吧,不管你有木有兴趣,哥要继续了。 在一些电视剧上,或许大家会经常看到这样的场景,男猪脚A为了了解或者认识某个人,某件事儿,往往会去当地的旅馆饭店向店小二打听、或者直接找到当地的地头蛇去了解情况。 无它,只是因为他们就像是一个当地各种事情各种人的活向导、活地图,他们可能对这些事情的始末了解的不够详尽,但是必然知道和这件事儿有牵连的人或者物。 所谓调查事情的始末,一张关系+事件网而已。 这种事情放到搜索引擎算法上,理所应当的同样成立,只不过角色道具全部发生了转换:男猪脚A变成了广大的搜索引擎用户,关系与事件网变成了链接组成的各种关系,而店小二与地头蛇变成了我们今天看到的各种让人倍感疑惑的站点。 将这些联系起来的,就是HITS算法。 先来看看百度百科的解释。 HITS算法:一个网页重要性的分析的算法,根据一个网页的入度(指向此网页的超链接)和出度(从此网页指向别的网页)来衡量网页的重要性。其最直观的意义是如果一个网页的重要性很高,则他所指向的网页的重要性也高。一个重要的网页被另一个网页所指,则表明指向它的网页重要性也会高。指向别的网页定义为Hub值,被指向定义为Authority值。
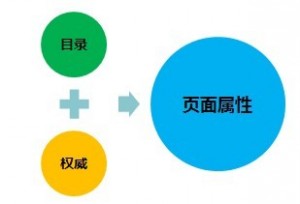
如果你木有看懂,木得关系,哥来继续给你说一下。 对于任何一个页面来说,其本身必然有两种属性:目录属性(还有人喜欢叫做枢纽)+权威属性。 目录属性即他本身会有出链,也会更像一个导航,告诉读者想看到关于某件事儿更详细的信息可以点链接出去查看;权威属性即每个页面都是基于某个主题所阐述的,这个页面也必然会有基于该主题的权威值,大小而已。
了解了这个,开始继续看下它是怎么运用到搜索引擎算法中去的。 在前面介绍搜索引擎原理的文章()中,我们介绍过搜索引擎是怎么处理页面并返回结果的,HITS算法正是在此基础之上开展起来的。下面来看详细的步骤。 1、查找根集合 将查询q提交给基于关键字查询的检索系统,从返回结果页面的集合中取前n个网页(如n=200),作为根集合(root set),记为S,则S满足: 1.1、S中的网页数量较少; 1.2、S中的网页是与查询q相关的网页; 1.3、S中的网页包含较多的权威(Authority)网页。 2、拓展相关页面 有了一些牛逼的权威页面,开始拓展相关页面。 其维度也只有两种:指向权威页面的和权威页面指向的。 要明白为什么这么拓展页面,需要先理解一句话: 一个权威页被多个目录页指向,说明这个权威页很权威;一个目录页指向了多个权威页,说明这个目录页很目录。 先解释一下:哥不是纯心跟您玩绕口令,自己先理解一下。 3、计算页面的权威值和目录值 有了一个相关的子集,也理解了上述的意思,开始计算各个页面的目录值和权威值。 计算公式很简单: 先来给个初始子集的集合P={p1,p2,p3…pn},然后根据这些页面之间的链接关系建立起一个矩阵:
如果页面1有链接指向页面2,则a12的值即为1,反之,则为0。 a页面的权威值即为指向它的所有目录页面的目录值之和; a页面的目录值则为它指向的所有权威页面的权威值之和。 4、返回结果 按照页面的目录值和权威值返回结果。 好了,聪明的同志应该也可以看到,这个算法是基于某一主题的,可以很好的反应出了人际关系中的一些特点,也能很好的反应出了互联网关系的一些特点。 它也会有一些比较恶心的不足之处,比如耗时(在返回结果之后再计算,会增加用户等待的时间),会发生主题漂移(不考虑内容,只考虑链接会造成本来在说A事情,可能结果变成了有一部分在说B事情)等等。 当然,从中我们可以看到一个事实,那就是其实搜索引擎的算法并木有传说中的那么神秘,很多也是基于人际关系为原型计算出来的(前面的PR算法()也一样),因为毕竟,搜索引擎算法工程师也是人,相比较来说,他们的优势在于怎么通过一系列的算法将这一原理变成机器可以读懂的现实。 本文首发于【SEO科学之美】 转载请注明链接地址: (责任编辑:admin) |