|
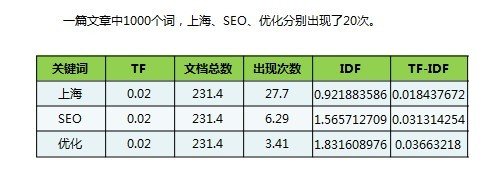
既然是二,就是顺着上一篇文章《TF-IDF:传统IR的相关排序技术》写下来的。所以,有兴趣的同学请先看完第一篇文章再来继续。 好,我们继续开始二。 关于词频,只要你的分词工具够牛逼,就很好理解和实现。关于反文档频率,各位亲们,看到时会不会初时感觉很牛叉,然后细想会很有疑惑? 逆文档频率(idf)=log(文档总数/包含关键词的文档数量) 对,疑惑就在怎么获得“文档总数”与“包含关键词的文档数量”上。 在搜索引擎上,可以有一个不错的替代方式,下面听我细细道来。 每篇文章每个网页几乎都含有“的”这个字,嗯,你想到了吧。在搜索引擎中搜这个字,出来的结果数量可以理解为所有的文档数量,然后再搜你的目标词即为包含这个词的文档数量,这一数据也就得到了解决,下面是我弄的一个例子:
好了,有了这些数据,我们接下来看看能够做些什么出来。 将网站中每个网页进行分词,去掉语气助词停顿词之后按照tf-idf值从大到小进行排序。 网页A={a1,b1,c1,d1,e1……z1} 网页B={a1,b2,c1,d5,e2……z6} 网页C={a2,b1,c2,d1,e2……z2} …… 显然从{a1,b1,c1,d1,e1……z1}中就可以了解到网页A所表达的意思,B、C亦然。 如果通过一个方法将A、B、C中的词进行比对,那岂不是就可以算出来……,你想对了,页面之间的相似程度。 这个方法,就是余弦值。具体操作,如下: 我们首先从A、B、C中选出前N个可以表达页面主题的词,组成一个集合。 {a1,c1,d1,e1,b2,d5,e2,a2,b1,c2} 然后计算A、B、C页面针对这个集合中每个词的词频(如有必要,请使用相对词频),组成对应的向量。 A=[2,1,3,5,0,0,0,0,1,0] B=[……] C=[……] 请记住这个高中时就学到的公式。
OK,经过此公式的计算,不但是页面之间的相似度,同样一个页面最相关的推荐文章也即可由此产生。 有兴趣的同学们,请试验一下吧。 转载请注明链接地址。 (责任编辑:admin) |