|
很多刚入行的SEO朋友,网站日志分析都不陌生,但对于真假百度蜘蛛还是无法辨别,摸不着头脑。站长在分析网站日志会看到百度蜘蛛来爬行我们的网页,随着技术越来越发达,很多的采集程序也会冒充百度蜘蛛来爬行我们的网站,导致我们无法辨出哪个才是真的百度蜘蛛,笔者根据自己操作经历,给大家分享如何辨出真假百度蜘蛛?
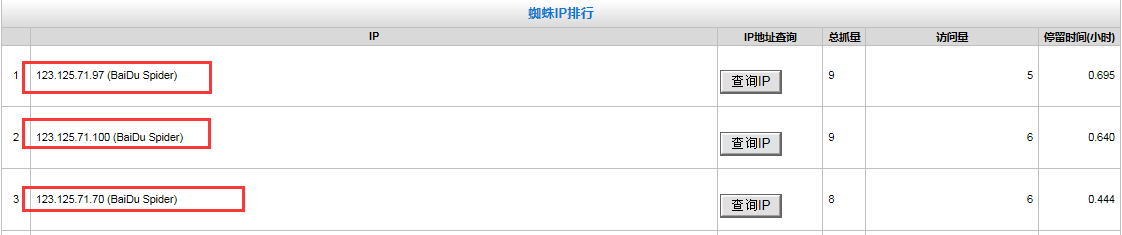
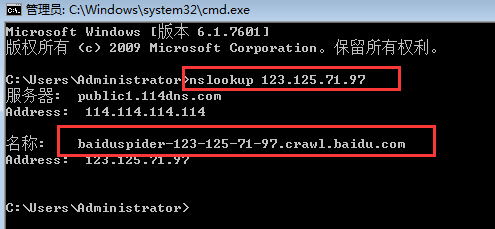
针对Apache服务器,使用光年日志分析工具结果可以看到,当天蜘蛛抓取网站的ip排行情况,我们针对这三个ip来验证真假百度蜘蛛,有两种验证方法: 1、点击开始,搜索中输入“cmd”命令符,接着输入“nslookup+ip”出现的结果如下,可以看到结果显示名称“baiduspider-123-125-71-97.crawl.baidu.com”,说明这个是真的百度蜘蛛。
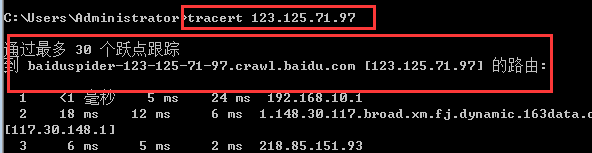
2、点击开始,搜索中输入“cmd”命令符,接着输入“tracert+ip”出现的结果如下,可以看到结果显示名称“baiduspider-123-125-71-97.crawl.baidu.com [123.125.71.97]”,这个也是真的百度蜘蛛。
接下来我们来看看假百度蜘蛛的例子: 这是朋友负责的一家电商网站,我看了下该网站的日志,截图如下:
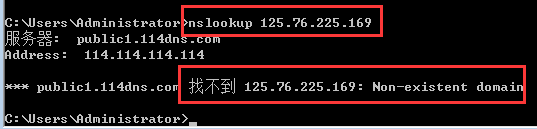
对以上3个ip用命令符“nslookup+ip”查询的结果如下:
假蜘蛛的危害:1、占用网络带宽,无效流量上涨。2、在有限的带宽情况下,影响正常蜘蛛抓取网页。3、对我们SEO工作产生干扰。 希望通过这篇文章,SEO新手能正确辨别真假百度蜘蛛,可以避免网站不必要的损失,让SEO工作正常进行。文章由99医院大全提供:yyk.99.com.cn转载注明出处。 (责任编辑:admin) |