|
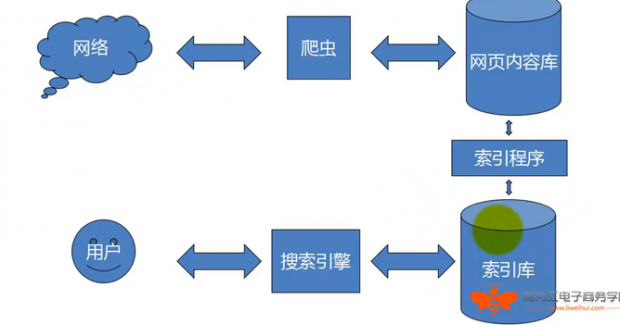
什么是网络爬虫呢?其实啊,很简单,网络爬虫就是搜索引擎访问你的网站进而收录你的网站的一种内容采集工具。例如:百度的网络爬虫就叫做BaiduSpider。 俗话说:知己知彼,百战百胜。 接下来想必你会问网络爬虫的工作原理是什么呢?下面我给大家看一张图:
这张图就能很充分的说明搜索引擎的Spider的工作原理: Spider通过互联网上所有的锚文本和链接进入你的网站采集你网站的网页面里的内容,把这些采集到的内容存放到网页内容库里面,然后百度通过整理索引内容程序制作一个索引库,让用户通过搜索引擎可以很快的找到它想要的东西。这就是搜索引擎网络爬虫的工作原理。 知道了网络爬虫的原理,如何做好SEO呢?只要记住一点,搜索引擎永远最偏爱稀缺的优质的内容,所以要保持网站内容的更新频率和质量就能得到Spider的好感,那么之后你的网站就会和Spider坠入爱河了。那么怎么才能知道你的另一半Spider有没有来过你的网站呢?很简单,你可以通过查看你的空间上的logs文件,下面一张图告诉你怎么查看日志:
为什么文章被收录,搜索量没有发生变化呢? 这就要从你自己身上找原因了,因为被蜘蛛抓取的内容在搜索引擎索引库里面是重复的,这篇文章就被认为是一点卵用也没有了。 另外你可能也会遇到另外一种情况,那就是你在新浪博客和你的网站都发表了同一篇文章,但是你的文章在新浪博客上被收录了,自己的网站上却没有被收录,这种原因其实很简单,就是因为新浪博客的名气大,权重高,所以排名会比你的网站高,当然这种状况是可以改变的,那就是好好做你的网站,把网站的内容做的很专一,那么Spider就会更加偏爱你了。 转载请注明商丘郭勇SEO技术分享学习博客()分享从菜鸟到大神的SEO知识教程 (责任编辑:admin) |