|
我们测试了谷歌爬虫是如何抓取 JavaScript,下面就是我们从中学习到的知识。 认为 Google 不能处理 JavaScript ?再想想吧。Audette Audette 分享了一系列测试结果,他和他同事测试了什么类型的 JavaScript 功能会被 Google 抓取和收录。
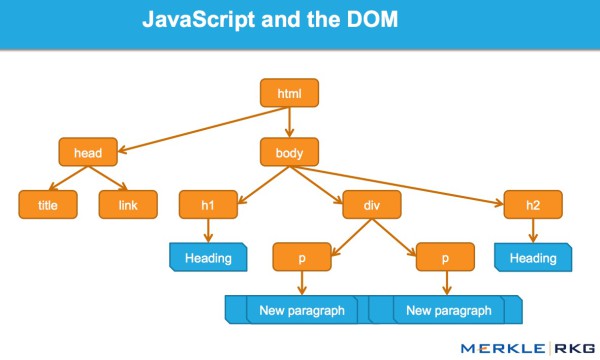
概述 1. 我们进行了一系列测试,已证实 Google 能以多种方式执行和收录 JavaScript。我们也确认 Google 能渲染整个页面并读取 DOM,由此能收录动态生成的内容。 2. DOM 中的 SEO 信号(页面标题、meta 描述、canonical 标签、meta robots 标签等)都被关注到。动态插入 DOM 的内容都也能被抓取和收录。此外,在某些案例中,DOM 甚至可能比 HTML 源码语句更优先。虽然这需要做更多的工作,但这是我们好几个测试中的一个。 引言:Google 执行 JavaScript & 读取 DOM 早在 2008 年, Google 就 成功抓取 JavaScript,但很可能局限于某种方式。 而在今天,可以明确的是,Google 不仅能制定出他们抓取和收录的 JavaScript 类型,而且在渲染整个 web 页面上取得了显著进步(特别在最近的 12 到 18 个月)。 在 Merkle,我们的 SEO 技术团队想更好地理解谷歌爬虫能抓取和收录什么类型的 JavaSscript 事件。经过研究,我们发现令人瞠目的结果,并已证实 Google 不仅能执行各种 JavaScript 事件,而且能收录动态生成的内容。怎么样做到的?Google 能读取 DOM。 DOM 是什么? 很多搞 SEO 的都不理解什么是 Document Object Model(DOM)。
当浏览器请求页面时会发生什么,而 DOM 又是如何参与进来的。 当用于 web 浏览器,DOM 本质上是一个应用程序的接口,或 API,用于标记和构造数据(如 HTML 和 XML)。该接口允许 web 浏览器将它们进行组合而构成文档。 DOM 也定义了如何对结构进行获取和操作。虽然 DOM 是与语言无关的 API (不是捆绑在特定编程语言或库),但它普遍应用于 web 应用程序的 JavaScript 和 动态内容。 DOM 代表了接口,或“桥梁”,将 web 页面与编程语言连接起来。解析 HTML 和执行 JavaScript 的结果就是 DOM。web 页面的内容不(不仅)是源码,是 DOM。这使它变得非常重要。
JavaScript 是如何通过 DOM 接口工作的。 我们兴奋地发现 Google 能够读取 DOM,并能解析信号和动态插入的内容,例如 title 标签、页面文本、head 标签和 meta 注解(如:rel = canonical)。可阅读其中的完整细节。 关于这一系列测试、及结果 因为想知道什么样的 JavaScript 功能会被抓取和收录,我们单独对 谷歌爬虫 创建一系列测试。通过创建控件,确保 URL 活动能被独立理解。下面,让我们详细划分出一些有趣的测试结果。它们被分为 5 类: JavaScript 重定向 JavaScript 链接 动态插入内容 动态插入 Meta 数据 和页面元素 一个带有 rel = “nofollow” 的重要例子
例子:一个用来测试谷歌爬虫理解 JavaScript 能力的页面。 1. JavaScript 重定向 我们首先测试了常见的 JavaScript 重定向,用不同方式表示的 URL 会有什么样结果呢?我们选择了window.location 对象进行两个测试:Test A 以绝对路径 URL 调用 window.location,而 Test B 使用相对路径。 结果:该重定向很快被 Google 跟踪。从收录来看,它们被解释为 301 - 最终状态的 URL 取代了 Google 收录里的重定向 URL。 在随后的测试中,我们在一个权威网页上,利用完全相同的内容,完成一次利用 JavaScript 重定向到同一个站点的新页面。而原始 URL 是排在 Google 热门查询的首页。 结果:果然,重定向被 Google 跟踪,而原始页面并没有被收录。而新 URL 被收录了,并立刻排在相同查询页面内的相同位置。这让我们很惊喜,以排名的角度上看,视乎表明了JavaScript 重定向行为(有时)很像永久性的 301 重定向。 下次,你的客户想要为他们的网站完成 JavaScript 重定向移动,你可能不需要回答,或回答:“请不要”。因为这似乎有一个转让排名信号的关系。支持这一结论是引用了 Google 指南: (责任编辑:admin) |