|
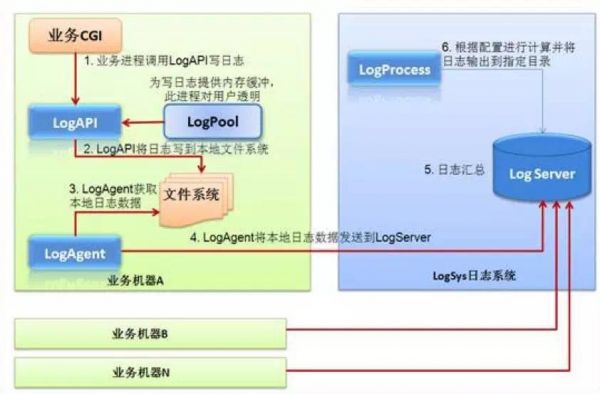
数据采集分为两步,第一步从业务系统上报到服务器,这部分主要是通过cgi或者后台server,通过统一的logAPI调用之后,汇总在logServer中进行原始流水数据的存储。当这部分数据量大了之后,需要考虑用分布式的文件存储来做,外部常用的分布式文件存储主要是HDFS。这里就不细展开。 原始数据上报存储到文件的架构图 数据存储到文件之后,第二步就进入到ETL的环节,ETL就是指通过抽取(extract)、转换(transform)、加载(load)把日志从文本中,基于分析的需求和数据纬度进行清洗,然后存储在数据仓库中。 以腾讯为例子:腾讯大数据平台现在主要从离线和实时两个方向支撑海量数据接入和处理,核心的系统包括TDW、TRC和TDbank。
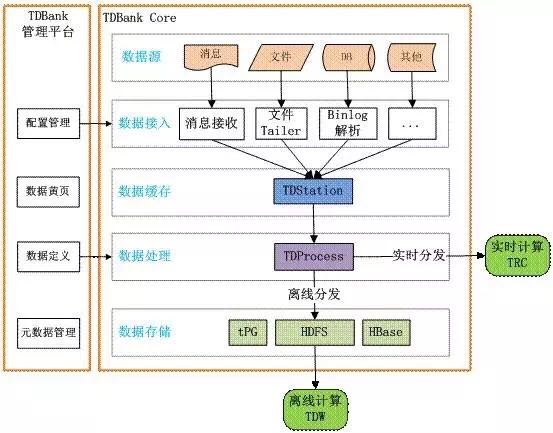
腾讯数据平台系统 在腾讯内部,数据的数据收集、分发、预处理和管理工作,都是通过一个TDBank的平台来实现的。整个平台主要解决在大数据量下面数据收集和处理的量大、实时、多样的问题。通过数据接入层、处理层和存储层这样的三层架构来统一解决接入和存储的问题。 (1)接入层 接入层可以支持各种格式的业务数据和数据源,包括不同的DB、文件格式、消息数据等。数据接入层会将收集到的各种数据统一成一种内部的数据协议,方便后续数据处理系统使用。 (2)处理层 接下来处理层用插件化的形式来支持多种形式的数据预处理过程。对于离线系统来说,一个重要的功能是将实时采集到的数据进行分类存储,需要按照某些维度(比如某个key值+时间等维度)进行分类存储;同时存储文件的粒度(大小/时间)也是需要定制的,使离线系统能以指定的的粒度来进行离线计算。对于在线系统来说,常见的预处理过程如数据过滤、数据采样和数据转换等。 (3)数据存储层 处理后的数据,使用HDFS作为离线文件的存储载体。保证数据存储整体上是可靠的,然后最终把这部分处理后的数据,入库到腾讯内部的分布式数据仓库TDW。
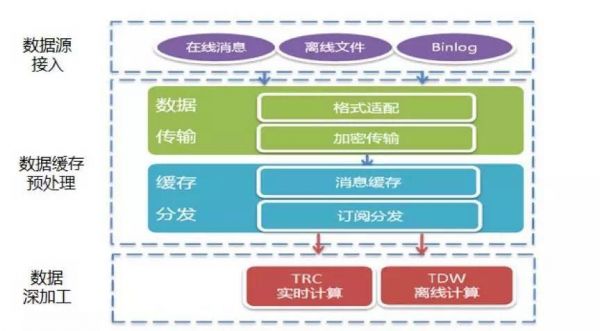
TDW架构图 TDBank是从业务数据源端实时采集数据,进行预处理和分布式消息缓存后,按照消息订阅的方式,分发给后端的离线和在线处理系统。
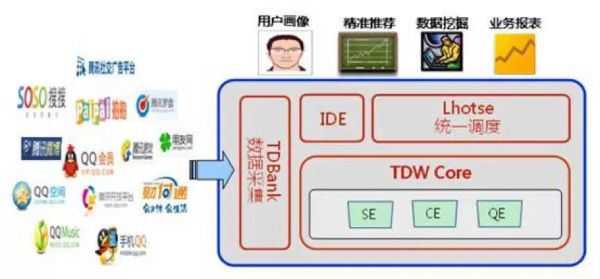
TDBank数据采集与接入系统 TDBank构建数据源和数据处理系统间的桥梁,将数据处理系统同数据源解耦,为离线计算TDW和在线计算TRC平台提供数据支持。目前通过不断的改进,将以前Linux+HDFS的模式,转变为集群+分布式消息队列的模式,将以前一天才能处理的消息量缩短到2秒钟! 从实际应用来看,产品在考虑数据采集和接入的时候,主要要关心几个纬度的问题: 多个数据源的统一,一般实际的应用过程中,都存在不同的数据格式来源,这个时候,采集和接入这部分,需要把这些数据源进行统一的转化。 采集的实时高效,由于大部分系统都是在线系统,对于数据采集的时效性要求会比较高。 脏数据处理,对于一些会影响整个分析统计的脏数据,需要在接入层的时候进行逻辑屏蔽,避免后面统计分析和应用的时候,由于这部分数据导致很多不可预知的问题。 2. 数据的存储与计算 完成数据上报和采集和接入之后,数据就进入存储的环节,继续以腾讯为例。 在腾讯内部,有个分布式的数据仓库用来存储数据,内部代号叫做TDW,它支持百PB级数据的离线存储和计算,为业务提供海量、高效、稳定的大数据平台支撑和决策支持。基于开源软件Hadoop和Hive进行构建,并且根据公司数据量大、计算复杂等特定情况进行了大量优化和改造。 从对外公布的资料来看,TDW基于开源软件hadoop和hive进行了大量优化和改造,已成为腾讯最大的离线数据处理平台,集群各类机器总数5000台,总存储突破20PB,日均计算量超过500TB,覆盖腾讯公司90%以上的业务产品,包含广点通推荐,用户画像,数据挖掘和各类业务报表等,都是通过这个平台来提供基础能力。
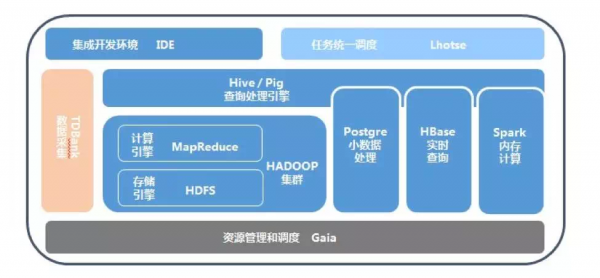
腾讯TDW分布式数据仓库
TDW业务示意图 从实际应用来看,数据存储这部分主要考虑几个问题: 数据安全性,很多数据是不可恢复的,所以数据存储的安全可靠永远是最重要的。一定要投入最多的精力来关注。 数据计算和提取的效率,做为存储源,后面会面临很多数据查询和提取分析的工作,这部分的效率需要确保。 数据一致性,存储的数据主备要保证一致性。 第9步、获取数据 就是产品经理,数据分析人员从数据系统获得数据的过程,常见的方式是数据报表和数据提取。 (责任编辑:admin) |