|
2017年7月7日,百度正式推出“飓风算法”
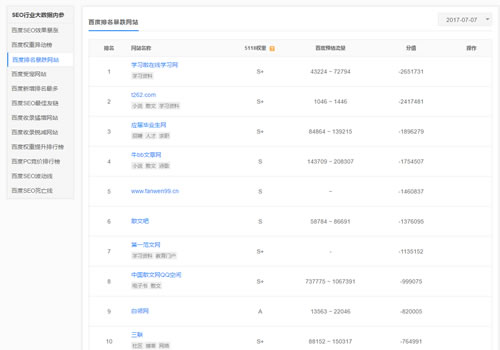
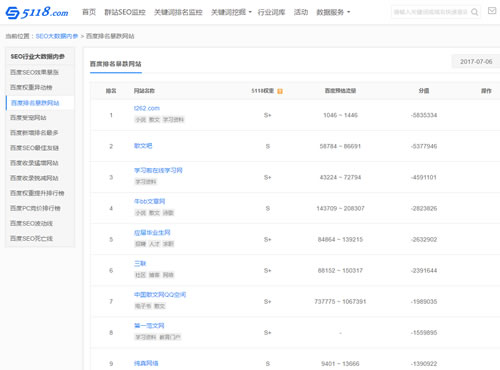
从官方文档中来看,飓风算法的命中对象是站点,而不是网页;主要是针对以恶劣采集为内容主要来源的网站,而不是所有包含恶劣内容的站点。 哪些内容算是恶劣采集?恶劣采集内容,一般是指没有花费时间,精力,专业能力,人工整合的内容,或者说对用户没有任何附加价值的内容。 这部分内容有以下几种类型: 1、从其他站点采集的内容 包括整个页面内容都是采集、主题内容是采集,或者多篇采集拼凑成的内容。这种类型内容很容易被识别。 2、采集之后轻度加工的内容 包括修改了部分词语,修改了部分句子,或者使用单词批量替换的形式(部分伪原创工具)。这种类型的识别难度稍微大一点。 3、从某些动态站点采集的内容 包括采集其他搜索引擎的搜索结果,采集新闻feed流。 注意几个要点:主体内容、恶劣采集、附加价值。 哪些内容不算是恶劣采集? 也有朋友问,为什么有些网站也是采集的,但没有受到影响,比如某doc、某浪。其实只要做到某个要点,就不算是恶劣采集,这个要点就是:给用户带来附加价值。 附加价值有站点增益和内容增益两种。这个时候可以引用百度搜索技术博客《浅谈互联网页面价值》的一段内容: 某人发表了一篇针对某新闻事件的原创博客,随后被新浪转载到了新闻频道。从描述的内容上讲,这是一种重复。但这种重复仅仅是主体内容上的重复,一方面它的转载带来了访问速度、稳定性等方面的增益,并且之后的检索用户还有可能用“新闻事件+新浪”来检索此新闻。这可以被称之为站点增益。另一方面,它在转载过程中可能会改变页面的标题,而且依托其受众,在转载页面上,还有可能出现更多的有价值评论和回复等,还有可能存在指向其它相关事件的新闻链接。这些可以被称之为内容增益。因此即使主题内容没有任何变化,新浪的这次转载也是有价值的,其稀缺度也是较高的。 同样,反过来说,如果转载的网站相当不知名,则其无法带来站点名/稳定性/速度的增益。更有甚者,转载之后在页面上加入大量广告妨碍阅读,或者只转载了内容中不完整的一部分,这样的转载,或者说采集,就是纯重复的,与采集源相比,就是没有检索价值的了。 综上所述,对于主体内容重复的页面,我们应该评价其是否存在站点增益和内容增益,只有对于大量完全无增益的重复页面,我们才应该认为其稀缺度较低。 这里的要点是:页面价值、增益 因此说,只要能够带来站点增益,内容增益,给用户带来附加价值,那就表明这个网页有其独特的价值,是不会被飓风算法命中的。 自百度推出“飓风算法”,首先中招的有这些大家熟悉的站。 7月7日中枪网站,大部分是范文类
7月6日中枪网站,大部分是范文类
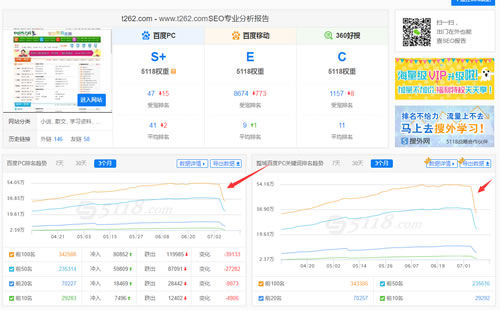
躺枪案例:
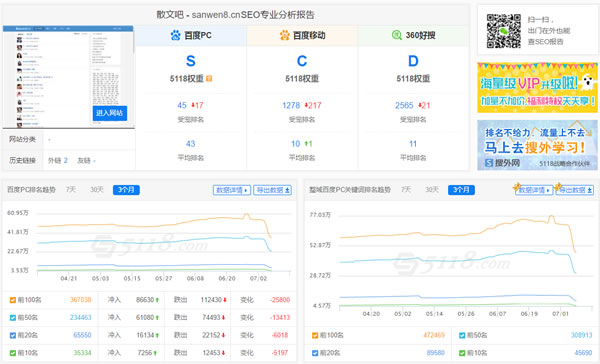
t262.com
sanwen8.cn 被飓风算法影响怎么办? 针对飓风算法的影响,百度一个朋友透露说: 飓风算法主要是针对没有价值的采集,一旦中招没有任何解法。而被误伤的优质原创可以通过反馈中心申诉。 因此,一旦被飓风算法命中,只要不是明显误伤,短期内都没有办法解决。(被搜素引擎算法命中,一般都是普遍存在的,不被搜素引擎接受的做法,一般没办法申诉,Google也是如此。只有人工处理的能申诉。) 如何避免被飓风算法命中 (责任编辑:admin) |