|
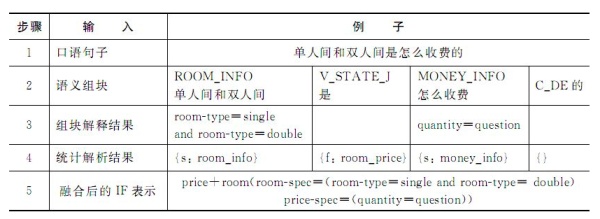
不同应用的 分词颗粒度大小是不同的,早期谷歌的分词采用Basic Technology公司的通用分词器,分词结果没有针对搜索进行优化,后期还专门为搜索设计和实现了自己的分词系统。 2, 句法分析(syntactic parsing) 文中的解释是句法分析是自然语言处理中的关键技术之一,其基本任务是确定句子的句法结构。 其实说简单点, 我的理解是,中文分词是把一句话拆分成 word1, word2, word3,那么句法分析就是把一句拆分成 主语,谓语,宾语….。 通过句法分析,能够更快的理解一句话,比如在理解英文对话的时候,虽然有些形容词看不懂,但是我们找到动词和主语或宾语后,能够大致知道这句话的意思。 基于概率上下文无关文法(probabilistic (或stochastic)context-free grammar, PCFG或SCFG)的短语结构分析方法可以说是目前最成功的语法驱动的统计句法分析方法,有兴趣的可以深入了解下。 3,语义分析 语义分析主要是词义消歧和语义角色标注。 词义消歧主要是因为一词多义非常普遍,如,英语中的单词bank的含义可以是“银行”,也可以是“河岸”,到底是哪个需要根据上下文环境,自动排除歧义。 比如 “ take me to the bank in the north “ 到底是去北边的银行还是去北边的河岸。 词义消歧方法分为有监督的消歧方法(supervised disambiguation)和无监督的消歧方法(unsupervised disambiguation)。在有监督的消歧方法中,可以根据训练数据得知一个多义词所处的不同上下文与特定词义的对应关系,那么,多义词的词义识别问题实际上就是该词的上下文分类问题,一旦确定了上下文所属的类别,也就确定了该词的词义类型。 在无监督的词义消歧中,由于训练数据未经标注,因此,首先需要利用聚类算法对同一个多义词的所有上下文进行等价类划分,如果一个词的上下文出现在多个等价类中,那么,该词被认为是多义词。然后,在词义识别时,将该词的上下文与其各个词义对应上下文的等价类进行比较,通过上下文对应等价类的确定来断定词的语义。 4,篇章分析 篇章在英文中常用“discourse”表示,在汉语里常有篇章、语篇或者话语之说。篇章分析的最终目的是从整体上理解篇章,最重要的任务之一是分析篇章结构。 在对话的过程中我们很少长篇大论,但是在多轮对话时,一整段对话其实是一个篇章。所以需要理解每句话之间或者说篇章的结构。 比如:“ 帮我定个明天早上7点的闹钟“ “ 算了,太早了,帮我改成8点“ 那么通过理解两句话的结构,我们知道需要去取消之前7点的闹钟,并设置一个8点的闹钟。 四,人机对话系统的实现技术 下面是《统计自然语言处理》里介绍的一种口语解析方法——基于规则和HMM的统计解析方法,文章并没有说这是人机对话系统的标准实现技术,而且表示这种做法有一定缺陷。 我们只需要了解这种根据词汇分类,语义组块分析后生成机器能够理解的对话分析机制。 基于规则和HMM的统计口语解析方法是 由词汇分类模块对其词汇进行词义分类,即把句子中的每一个词映射到相应的词义类中。语义组块分析器从句子对应的词义类序列中分析出语义组块,组块分析器输出的是一个语义组块序列。统计解析模块从语义组块序列分析出句子IF表示的主要框架。语义组块解释模块把各个语义组块解释为相应的IF表达式片段。 经过对上述两部分的合并,得到最终的IF(interchange format)表达式(国际语音翻译先进研究联盟C-STAR采用的一种称作中间转换格式的语义表示形式,以有利于多语言互译)。
1,IF表达式格式: Speaker:Speech-Act[+Concept]*[(Argument=Value[,Argument=Value]*)] 例:明天我想预订一个单人间。 IF:c:give-information+reservation+room(room-spec=(room-type=single, quantity=1), reservation-spec=(time=(relative-time=tomorrow))) (责任编辑:admin) |