|
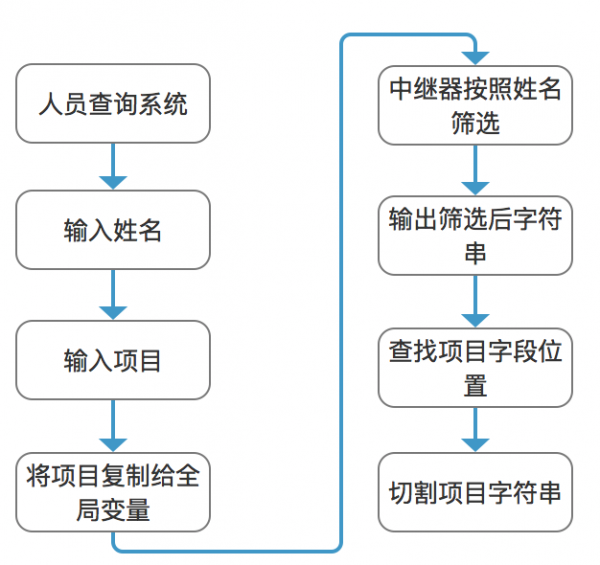
这下明白了吗?还要记住一点,就是substring函数截取的时候,是保留前面的第一个字符,不保留最后面的字符。所以当读取到第一个’,’的时候,要从它后面开始截取,一直到第二个’,’出现为止。 挑战升级 不知道还有几个人能看到这里,因为大部分人可能还是抱着一个失望的态度,『看了半天你就告诉我怎么截取字符串吗?老子800年前就会了,这跟数据库查的太远了吧,我怎么能随便查询任意参数呢?』 别急,上面都是基础,干货来了。 需要函数: Repeater.text 确保中继器返回的是字符串 split(”) 按照特定分隔符分割字符串 substring(from,to) 按照指定位置分割字符串 indexOf() 查找某个字符串在字符串出现位置 concat() 连接字符串 length 获取字符串长度 场景设计 学校有一个【人员管理系统】,系统里包含所有学生的姓名、学院、电话、年龄等各种信息。使用者可以通过姓名查询学生的任意其他特定信息,也可以修改任意信息。 例如:查询王刚的班级,查询邓爽的电话号码等。 构架分析 由需求得知我们需要查询指定姓名人员的某项信息,即数据库中特定行中的某项。由上文得知,我们可以通过筛选中继器方式得到指定行数据,即指定姓名的所有信息。然后通过切割字符串的方式查找到指定项目的信息。
在整个环节中,只有「查找项目字段位置」是个难点,因为项目是不确定的,在输出后的字符串中,只有按照「,」分割的数据内容,并不能知道每个数据代表着什么,所以如何查找指定项目的位置呢? 这里我们引入了一个类似「列名」的辅助字段,即将所有的数据内容前面加上一个列名标识,例如: 姓名中的数据变为 王刚——name_王刚 班级中的数据变为 通信信息——class_通信信息 手机中的数据变为 23456——phone_23456 年龄中的数据变为 22——age_22 这样我们获得某一行的字符串数据就变化成了: 王刚,通信信息,23456,22—— name_王刚,class_通信信息,phone_23456,age_22 看到了吗?我们得到了一个有标识的字符串,相信有些人已经想明白了,我们在字符串中通过数据前面的标识就可以判断每个数据是什么意思了。如果想得到班级,识别’class_’,如果想得到年龄,识别’age_’就可以了,无论数据有多少项,无论它位置在哪,只要我们指定想要数据的标识就可以了。 系统搭建 优化数据表 将原有数据按照指定数据格式优化(关于在excel中为同一列中每项数据增加字符的方法有很多),优化后添加到中继器数据中。
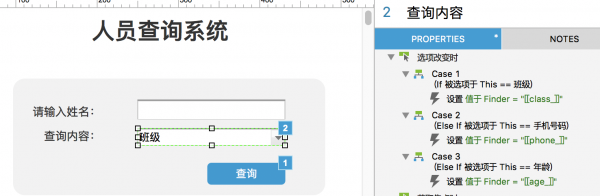
设置全局变量 首先设置一个表示查询项目的变量「Finder」,通过查询的项目内容为「Finder」赋值。 之后设置每个查询项目对应的特定前缀,name_、class_等。 设置查询面板 查询面板包括姓名文本框,查询项目列表框,查询按钮。 当切换查询项目时,系统将查询项目赋值给项目变量「Finder」,项目变量默认值与查询项目列表默认值相同。
当点击查询按钮时,将「姓名」赋值给全局变量「Name」,然后按照「姓名」文本框筛选中继器数据,之后按照项目变量「Finder」将具体项目数值显示到查询结果中。
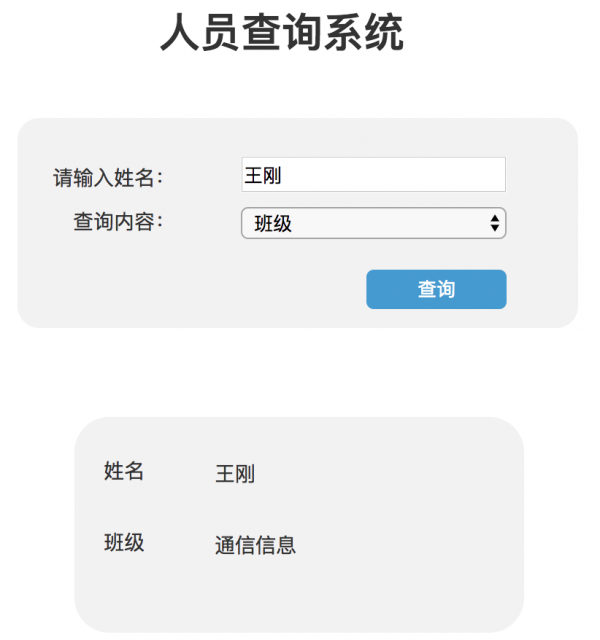
设置查询结果面板 查询结果包括姓名及查询内容结果,对应文本框显示相应信息即可,在此不再赘述。
函数分析 以下是查询结果显示的函数: [[A2.text.split(‘\n’).concat(‘,’).substring((A2.text.split(‘\n’).indexOf(Finder)+Finder.length),A2.text.split(‘\n’).concat(‘,’).indexOf(‘,’,(A2.text.split(‘\n’).indexOf(Finder))))]] 如果上文看懂的人会发现这里有几个特殊的地方: A2.text.split(‘\n’).concat(‘,’):在重新排列字符串最后加一个’,’,为了防止查找不到最后一个’,’而出现bug。 A2.text.split(‘\n’).indexOf(Finder)+Finder.length:因为Finder字符串长度的不确定性,切割的起始位置是从「Finder」字符串后开始切割的。 系统优化 (责任编辑:admin) |