|
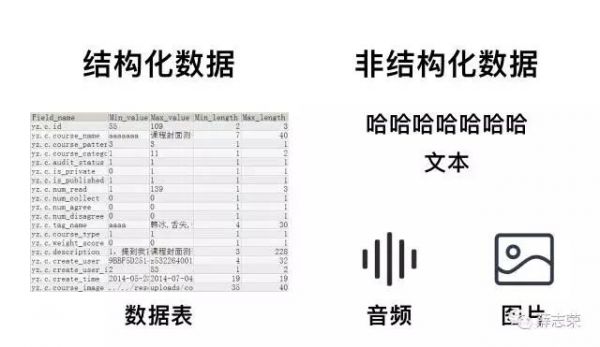
在计算机理念来说,人工智能是用来处理不确定性以及管理决策中的不确定性。意思是通过一些不确定的数据输入来进行一些具有不确定性的决策。从目前的技术实现来说,人工智能就是深度学习,它是06年由Geoffrey Hinton所提出的机器学习算法,该算法可以使程序拥有自我学习和演变的能力。 机器学习和深度学习是什么? 机器学习简单点说就是通过一个数学模型将大量数据中有用的数据和关系挖掘出来。机器学习建模采用了以下四种方法: 监督学习与数学中的函数有关。它需要研究学者不断地标注数据从而提高模型的准确性,挖掘出数据间的关系并给出结果。 非监督学习与现实中的描述(例如哪些动物有四条腿)有关。它可以在没有额外信息的情况下,从原始数据中提取模式和结构的任务,它与需要标签的监督学习相互对立。 半监督学习,它可以理解为监督学习和半监督学习的结合。 增强学习,它的大概意思是通过联想并对比未来几步所带来的好处而决定下一步是什么。 目前机器学习以监督学习为主。 深度学习属于机器学习下面的一条分支。它能够通过多层神经网络以及使用以上四种方法,不断对自身模型进行自我优化,从而发现出更多优质的数据以及联系。 目前的AlphaGo正是采用了深度学习算法击败了人类世界冠军,更重要的是,深度学习促进了人工智能其他领域如自然语言和机器视觉的发展。目前的人工智能的发展依赖深度学习,这句话没有任何问题。 人工智能基础能力 在了解人工智能基础能力前,我们先聊聊更底层的东西——数据。计算机数据分为两种,结构化数据和非结构化数据。结构化数据是指具有预定义的数据模型的数据,它的本质是将所有数据标签化、结构化,后续只要确定标签,数据就能读取出来,这种方式容易被计算机理解。非结构化数据是指数据结构不规则或者不完整,没有预定义的数据模型的数据。非结构化数据格式多样化,包括了图片、音频、视频、文本、网页等等,它比结构化信息更难标准化和理解。
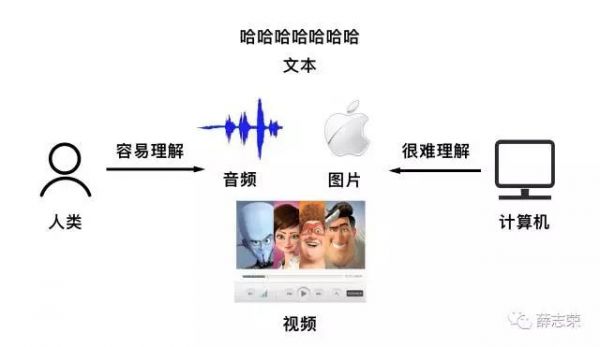
音频、图片、文本、视频这四种载体可以承载着来自世界万物的信息,人类在理解这些内容时毫不费劲;对于只懂结构化数据的计算机来说,理解这些非结构化内容比登天还难,这也就是为什么人与计算机交流时非常费劲。
全世界有80%的数据都是非结构化数据,人工智能想要达到看懂、听懂的状态,必须要把非结构化数据这块硬骨头啃下来。学者在深度学习的帮助下在这领域取得了突破性成就,这成就为人工智能其他各种能力奠定了基础。 如果将人工智能比作一个人,那么人工智能应该具有记忆思考能力,输入能力如视觉、听觉、嗅觉、味觉以及触觉,以及输出能力如语言交流、躯体活动。以上能力对相应的术语为:深度学习、知识图谱、迁移学习、自然语言处理、机器视觉、语音识别、语音合成(触觉、嗅觉、味觉在技术研究上暂无商业成果,躯体活动更多属于机器人领域,不在文章中过多介绍) 简单点说,知识图谱就是一张地图。它从不同来源收集信息并加以整理,每个信息都是一个节点,当信息之间有关系时,相关节点会建立起联系,众多信息节点逐渐形成了图。知识图谱有助于信息存储,更重要的是提高了搜索信息的速度和质量。 迁移学习把已学训练好的模型参数迁移到新的模型来帮助新模型训练数据集。由于大部分领域都没有足够的数据量进行模型训练,迁移学习可以将大数据的模型迁移到小数据上,实现个性化迁移,如同人类思考时使用的类比推理。迁移学习有助于人工智能掌握更多知识。 自然语言处理是一门融语言学、计算机科学、数学于一体的学科,它是人工智能的耳朵-语音识别和嘴巴-语音合成的基础。计算机能否理解人类的思想,首先要理解自然语言,其次拥有广泛的知识,以及运用这些知识的能力。自然语言处理的主要范畴非常广,包括了语音合成、语音识别、语句分词、词性标注、语法分析、语句分析、机器翻译、自动摘要等等、问答系统等等。 (责任编辑:admin) |