|
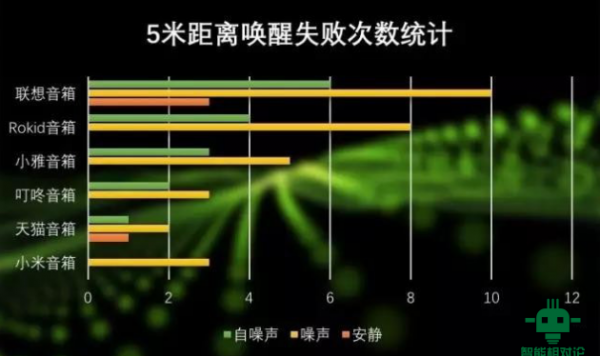
说到这里就不得不提到智能音箱,其实除搜狗之外,很多大公司也在布局语音交互,国内有阿里巴巴、百度、科大讯飞,国外有苹果、谷歌、微软、亚马逊。在今年7月阿里巴巴就发布了一款智能音响天猫精灵,可以接受各种语音指令,搭载中文人机交流系统AliGenie,有望成为家庭智能小助手。在11月16日百度也推出了首款智能音响raven H,其采用19×19的点阵触摸屏,内置DuerOS 2.0语音交互系统,拥有语音和控制器两种交互方式。其余还有京东的叮咚智能音响,小米的小爱同学,喜马拉雅的小雅音响等智能音响产品。对于这些公司而言,似乎不出一个智能音响都不好意思说自己在人工智能领域混。 那智能音响到底与唇语识别有啥关系?大厂们纷纷推出智能音响的原因是看到了新型交互方式的大趋势,但是智能音响能够满足需求的场景较少,且智能音响还有两大顽疾——抗噪音能力与远场交互能力较低。 根据声学在线的测试,即便是市面上最主流的智能音响,在抗噪音能力与远场交互能力上的表现也不尽如人意,5米的中短距离上有很多失误。
(图为:5m 距离智能音响唤醒失败次数统计) 而且,传统语音交互对输入音频要求高,在背景噪音大时很容易失效,若人与机器再隔得远一点,失效的情况就更加严重了。但唇语识别就可以解决这两个问题。 若要快速普及,还有两个问题待解 自出现唇语识别技术出现起,就有声音说唇语识别是语言交互的高阶战,甚至可能带来一场革命。不过,根据观察,目前来说,唇语识别还不能快速普及。这主要的问题在: 1、摄像头录入存在很大的限制,不能完全满足日常交互需求 在目前的唇语识别系统中,获得的嘴唇视觉特征信息都是正向的,这就意味着你与它交互时,必须时刻正对着它,第一视角被其牢牢占据,这在真实应用场景下难以达到。要能够应用更多的场景,应该使人在侧着身子说话时也能被检测识别,这要求在人脸识别、唇的检测与定位方面研究出更强的定位、跟踪算法,提高算法的普适性,使之适用于非特定姿势和位置的识别定位,并且唇动识别技术也要提高,使之能处理非正向的、较不完整的视觉特征信息。 2、识别的准确度也是一个关键的问题,在有关安全的场景下,准确度是不容有差的 但我们知道其实口型与拼音序列是一对的多关系,如 zhi、chi、shi对应的口型序列是一样的,单纯利用视觉特征难以区分,会造成信息识别错误,处理这个问题,传统的技术方法是文法型语言模型,它基于人工编制的语言学文法,这种语言模型一般用于分析特定领域内的语句,无法处理大规模的真实文本。目前很多识别系统是人工限定的框架,在某一场景中对可能会出现的语句进行了很多设置,这是搜狗唇语识别系统在垂直场景(如车载)中表现得很好的原因,这同样也是它还不能大规模应用到其他场景的原因,因为要对所有场景进行设定,几乎是不可能的。 不过,我们依然要满怀信心,随着人类社会的发展,真实信息越来越多,处理数据的手段也越来越丰富,基于语料库的统计语言模型发展迅速,借助于统计语言模型的概率参数,可以估算出自然语言中每个句子出现的可能性,并通过对语料库进行深层加工、统计和学习,获取自然语言中的语言知识,从而可以处理大规模真实文本,并能识别出语言中细微的差别。目前在通用识别场景的准确率只有60%到70%,虽然稍显不足,但可以预见,随着大数据与人工智能的发展,未来的识别准确率会达到更高。 这看起来,一个新的时代正向我们迎面走来。 (责任编辑:admin) |