|
绝大部分用户的搜索页面,第一页只有10个结果,除去我自家产品,往往仅剩下7个左右,一般用户最多只会点击到第3页,那么我需要的优质站点其实不到30个就可以最大限度的满足用户体验。那么经过3-5年的布局,逐渐筛选出一些耐得住寂寞和认真做细节的站,这时候我再将这一部分算法进行调整,进而筛选出这些优质站点,推送给用户。当然,在做的过程中还有更多的参考因素,比如域名年龄、JS数量,网站速度等。 你们说,为什么当站文章中有大量相同时,会快速引起搜索引擎惩罚呢?这里我说的不是摘抄与原创的问题,而是你站内自己和自己的文章重复。之所以搜索引擎反应这么快,同时惩罚严厉,根本原因就是在你的文章中,他提取不到内容1。 好,经过这一系列处理,我已经获得了内容1与内容2了,下面该进行原创识别的算法了。现在基本上搜索引擎对于原创的识别,在大面上采用的是关键词匹配结合向量空间模型来进行判断。Google就是这么做的,在其官方博客有相应的文章介绍。这里,我就做个大白话版本的介绍,争取做到简单易懂。 那么,我通过分析内容1,得到内容1中权重最高的关键词k,那么按照权重大小进行排序,前N个权重最高的关键词的集合我命名为K,则K={k1,k2,……,kn},则每一个关键词都会对应一个其在页面中获取到的权重特征值,我将k1对应的权重特征值设定为t1,则前N个权重关键词对应的特征值集合则为T={t1,t2,……,tn},那么我们有了这个特征项,就能计算出其相对应的特征向量W={w1,w2,……,wn}。接着我将K拼成字符串Z,同时MD5(Z)则表示字符串Z的MD5散列值。 那么假定我判定的两个页面分别是i与j。则我计算出两个公式。 1.当MD5(Zi)=MD5(Zj)时,页面i与页面j完全相同,判断为转载。 2.设定一个特定值α
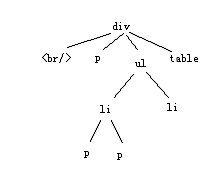
当0≤α≤1的时候,我判定页面相似为重复。 由此,对于原创文章的判断就结束了。好了,苦逼烦闷的枯燥讲解告一段落,下面我用大白话再重新复述一遍。 首先,你的内容一模一样,一个字都不带改的,那肯定是摘抄的啊,这时候MD5散列值就能迅速的判断出来。 其次,很多SEO他们懒,进行所谓的伪原创,你说你伪原创时插入点自己的观点与资料也成,结果你们就是改个近义词什么的,于是我就用到了特征向量,通过特征向量的判断,把你们这些低劣的伪原创抓出来。关于这个,判断思想很简单,你权重最高的前N个关键词集合极为相似的时候,判断为重复。这里所谓的相似包括但不仅仅局限于权重最高的前N个关键词重合,于是构建了特征向量,当对比的两个向量夹角与长度,当夹角与长度的差异度小于某个特定值的时候,我将其定义为相似文章。 一直关注google反作弊小组官方博客的朋友们,应该看过google关于相似文章判断算法的那篇博文,在那篇文章中,其主要使用的是余弦定理,就是主要计算夹角。不过后来Mr.Zhao又看了好几篇文献,觉得那篇博文应该仅仅是被google抛弃后才解密的,现在大体算法的趋势,应该是计算夹角与长度,所以选择现在给大家看的这个算法。好的,这里我们注意到了几个问题。 1.α被判定为重复时的取值范围是否可变? 2.内容中如何提取出关键词? 3.内容中关键词的权重值是如何赋予的? 下面我来逐一解答。 先说α判断重复时的取值范围,这个范围是绝对可变的。随着SEO行业的蓬勃发展,越来越多人想要投机取巧,而这是搜索引擎不能接受的。于是就会隔几年进行一次算法大更新,而且每一次算法大更新,都会预告会影响百分之多少的搜索结果。那这影响结果的百分数是如何计算出来的?当然不是一个一个数的,在内容方面(其它方面我会在其它文章中阐述),是通过调整α判断相似度时的取值空间变化来计算的,每一个页面在被我处理是,我所计算出的α值都会存储在数据库中,这样我在每次算法调整时,风险都可做到最大的控制。 那么如何提取关键词?这就是分词技术了,我待会再讲。页面内不同关键词的权重赋值也在待会讲。 关于文章相似性,简而言之,就是以前大家改一改文章,比如“越来越多SEO开始重视起文章的质量。”改为“高质量的文章被更多的SEO所重视”,这个在以前没有被识别出来,不是我没有识别你的技术,而是我放宽范围,我可以随时在需要的时候,通过设定参数的取值范围,来重新判断页面价值。 好,如果这里你有些糊涂,别着急,我接着慢慢的说。上述算法里,我需要知道前N个重要的关键词以及其所对应的权重特征值。那这些数值我如何获取呢? 首先,要先分词。针对于分词,我先设定一个流程,然后采用正向最大匹配、逆向最大匹配、最少切分等方式中的一种来进行分词。这个在我会在我的博文《常见的中文分词技术介绍》中讲解,在此不再赘述。通过分词,我得到了这个页面内容1的关键词集合K。 在识别内容1的时候,我就已经构建了标签树,那么我的内容1实际上已经被标签树拆解为由段落组成的树状结构了。
上图是内容1的标签树。在这里,我遇到一个问题,那就是针对标签树权重赋值的时候,应该是面向整个页面的标签树,还是仅仅面向内容1的标签树的? 很多朋友可能会认为,既然是针对内容1的关键词进行赋值判断,那只处理内容1就好了。其实不然。一款搜索引擎,其处理的数据少说也要千万级别的,所以搜索引擎对于高效率的代码与算法要求是极高的。 而正常情况下,一个网站的网页是不可能孤立存在的,在对一个页面针对某一个关键词进行排序的时候,除了要考虑站外因素外,我需要考虑站内权重的继承,那么在考虑站内权重继承的时候,我必然避不开内链的计算,同时内链本身也应该有不同的权重区分,而内链权重计算时,我肯定要考虑其所在页面与其相关性。既然如此,我就应该一次性对整个页面所有的信息块进行权重分配,这样才是高效率,同时也充分体现了内容与链接相关性的重要性。用一句大家常能在网上看见的话来说,就是相关性决定了链接投票的有效性。 好,既然确定下是整个标签树进行权重赋值,那么下面开始。首先,我要确定重要关键词的词库。重要关键词的确定通过两种方法: 1.不同行业的重点关键词。 2.针对句子结构与词性的重点关键词。 (责任编辑:admin) |