|
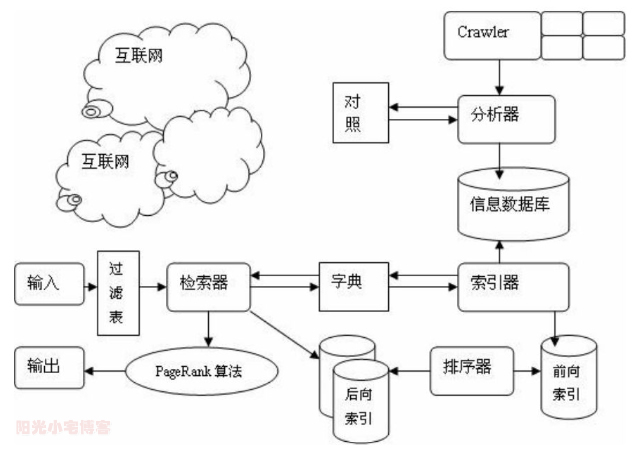
网站要在搜索引擎获得良好的流量,就一定要提高网站的收录,以站内页面更加多的潜在关键字尽可能在搜索排名上占领一席之地。国内网站普遍瞄准的SEO市场就是百度搜索引擎,可是站长到最后都会发现,除了收录首页之外,站内的页面寥寥无几。为何它现在都不再随便收录我们的内页?很多网站一直普遍做法就是在首页加上自己的主关键字,再在站内使用采集或者机器添加一些乱七八糟的文章,目的是用来维持网站在百度快照日期的“新鲜度”(阳光小宅博客认为这是毫无意义的事情)——互联网的车乱从没有停止过并且发展到今天,我认为这就是如今导致搜索引擎不再随便收录网页原因。如何才能让百度收录你的网站的更多页面信息,你就必须从搜索引擎收录机制的角度出发。 推测百度的收录机制,就要明白“蜘蛛”工作的原理 百度搜索引擎有一个俗称“蜘蛛”的自动程序(英文名是“Baiduspider”),它的作用是访问互联网上的网页、图片、视频等内容,建立索引数据库,使用户能在百度搜索引擎中搜索到您网站的网页、图片、视频等内容。搜索引擎的基本工作原理包括如下三个过程:首先在互联网中发现、搜集网页信息;同时对信息进行提取和组织建立索引库;再由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。
1、“蜘蛛”只不过是也采集器,只是比较先进而已。 作为全球最大的中文搜索引擎,面对着单单要处理的中文网站目前就有几百万个,那么网站内页的数量就如天上的繁星。现在从科学的角度来个假设,既然百度“蜘蛛”叫得上为自动程序,那么的是会越来越先进的东西(就像未来的机器人一样越来越智能了),让它们能够自动判断捕捉到的页面内容到底有没有用,有的话就直接把数据放进口袋,然后再根据当前页面的链接爬到新的页面来个循环捕捉,直到口袋装满了就把信息带回去给服务器经过一系列更加专业的计算去对比……去判断是否需要正式收录进数据库。整个过程就像采集器一样,按照预先设置好采集规则,然后过滤不符合规则的信息。 2、可能被判断会被收录进数据库的信息 我很多时都逛很多知名的数码网站,发现他们的内容很多都是千遍一律的互相采集(复制),并且没有作任何修改处理,居然还被各大搜索引擎收录展示。可怜的小站长辛苦采集了成千上万的数据,再苦等一段日子后,居然只有首页或大不了多几个站内页面被收录。是否有有人埋怨这太不公平了,为何他们采集数据可以被收录,而我的不行。百度搜索引擎收录机制其中有一个这样的参考因素,“权重”(就是搜索引擎对站点权威的判断)。 网站被“蜘蛛”捕捉过的第一天起就会一直监视网站的一举一动,并且给出该网站的域名一个“分数”作为衡量“权重”有多高。阳光小宅博客认为影响权重的其中一个主要因素,以“新浪网”为例,它被百度搜索引擎监测到很多独家内容(原创)从“第一现场”被转载到其它地方,还有很多带有文字链接和不带链接的静态网址、网站名称(新浪网、新浪)频繁地出现在各大小网站——也即“曝光率”。 其实搜索引擎这样的收录机制去处理数据是非常明智的,不但节省了时间、还减轻了服务器的负担,也是非常有经济效益的手段。 网站权重高低的收录待遇 假设:A站和B站等权重都为9分,大于C站权重为2分; (1)如果A站采集了B的内容,搜索引擎多数会收录,并快速显示搜索结果 (2)如果A站采集了C的内容,搜索引擎多数会收录,并快速显示搜索结果 (3)如果C站采集了A站、B站的内容,可能不会被收录,又或者就算收录了也要好几天会显示出搜索结果 高权重网站无论向是否同级别的网站获取内容会更容易被收录,并且会快速显示出来。因为高权重的网站在搜索引擎里面代表的是一种权威性、曝光度,所以搜索引擎就很可能会认为该网站提供的信息无论与否采集、历史是否悠久的内容对于网民很有可能是有一定需要。也意味着这个网站上的信息平时很多人浏览、传播速度很快,及时把内容收录起来并以最快速度向进行搜索的用户展示其相关结果是非常有必要的,从而提升用户在搜索引擎中的良好体验。
权重不太高的网站复制和转载一些目前热门或者比较过去式的内容,当这些内容被“蜘蛛”判断分析过后,发现该内容已经有很多尤其是高权重的网站转载过了,觉得没有必要再把数据带回去给搜索引擎的服务器进行处理。为什么要会这样判断?既然搜素引擎的数据库里面早已经有这样的信息,还是在一些高权重网站获取回来的,就算用户搜索与其相关信息时,也可以提供到很多相关内容,并且权威性也比较强。假如你是百度搜索引擎的工程师,当用户搜索“扁桃体炎”的时候,你也会告诉用户百度百科不错、某某健康网也挺专业的。搜索引擎作为用户的朋友不会无缘无故推荐一个江湖游医给你身边的人,弄不好还会给人臭骂一顿。 例如:某大型网站今天发布了去年已经被转载无数次的考试作文,由于权重高的网站搜索引擎对它有一种信任感,认为该他们提供这条信息一定是有必要性的才被重新发布。当有用户正在搜索以该作文有关的信息时,搜索引擎会查询数据库里拥有相关匹配的信息,然后再根据网站当前页面的权重高低以排名方式展示其搜索结果。把搜索引擎就像你的朋友一样,当你问百度哪里查找到有关“iPhone 4S”的最新消息?搜索引擎就会告诉你,我认识一堆江湖兄弟叫做太平洋、新浪、网易……它们好像知道,你去那里看看有没有相关资讯,如果没有你可以打开第二页或者继续往后看看一些不太熟悉的朋友有没有相关信息。 网站权重就是一个网站在搜索引擎的命根 (责任编辑:admin) |