|
注:实在不知道起什么题目为好,文章内容大部分是从个人使用体验而推导出的改进。本人不是搜索引擎的专业人士,权当是对之前所了解知识的整理得了。 一、搜索引擎原理和用户使用习惯 1.1 搜索引擎是一个可供所有人检索的数据库
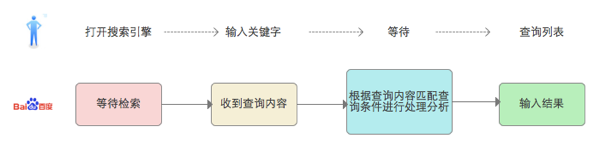
图1:搜索引擎简单的人机交互过程 其中: 1)被检索的数据库即搜索引擎所抓取的网页数据。 通过蜘蛛爬取到原始数据后,搜索引擎会对其进行处理后才入库。即搜索引擎的搜索算法,比如大家熟知名字(当然是名字啦,内容原理是最高机密)的Google的PageRank。 2)搜索引擎是高度简化后的产品。 用户需要做的即是输入想要检索的关键词,确定,查看结果。这里有个需要说明的是,用户连搜索条件都不需要输入。而对搜索引擎来讲,不仅要在海量数据中快速找到相关结果,还要揣测用户的期望并提取正确的内容给用户,内部的机制已经不能用繁琐来形容了。 这个难度就好比在大量图书中快速准确找出某一个未知问题的答案一样。
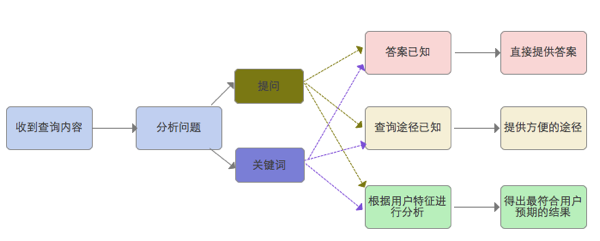
图2:刚拍摄的国家图书馆,使用了滤镜。 1.2 搜索引擎数据处理过程 搜索引擎是一个超级复杂的系统,内部具体的处理规则和技术原理不可能是简单的阐述清楚。我们通过产品的思维来理解一下这个过程即可。拿写论文的例子分析即可,论文在成文之前材料的整理过程大致如下: 1)从网络、图书馆、书籍杂志、讲座等等收集大量原始资料 2)排除相关重复内容 3)排除跟主题关联性不大的内容 4)根据主题、逻辑顺序、优先级等进行人为的计算、分析、排版、处理等。这个过程是最为繁琐和耗时的,使用的武器便是史上最牛逼的工具:人脑!!! 5)成文输入结果 忍不住再重申一下:所有的产品其实都是在模仿人类的实际社会活动。。。明白这个对于产品经理很重要哦。 搜索引擎数据处理流程基本类似(想要了解的可以自行搜索相关资料),唯一的也是搜索引擎想消除的区别: 一个是有感情有逻辑的人脑在分析,一个是机器按照一定规则来分析。 所以,想要搜索结果更精准,那就让它像人脑一样分析输入数据并输入结果。 恩,我也觉得不怎么现实,但是可以想办法让他比较精准。 二、获取信息的方式 我们还是先从日常行为的来入手然后再推导产品的操作方式。 2.1 通常,我们从周围环境如下获取信息: 1、 已知获取途径和方法 如想获知今天美元对人民币的汇率抑或北京飞青岛的机票价格和时刻表,因为途径已知,此类信息只要按图索骥即可。差别在于不同途径的成本。汇率可通过网络查询、电话咨询、银行网点询问等,显然第一种方法更便捷。(的确是废话)。 这些信息都是规则化,概念明确的。 2、了解核心关键需要整理的 如刚才提到的论文写作,假设题目为弱关系社区设计,我们就需要去询问什么弱关系,和强关系有什么区别,已有的设计案例是什么。 这些信息的获取建立在人为分析的前提下。 2.2 提问方式 还是举两个例子。 1、 在形成完整的序言逻辑前,小孩子提问的方式是最简单的关键词,大人们要做的便是通过他的咿呀来理解孩子的需求。一般大人都能准确预测,原因在于其非常了解孩子的习惯、行为、方式、特征等。 2、有了完整的语言逻辑后,我们一般选择直接提问:今天的汇率是什么?北京飞青岛的票价多少,都是几点的?人脑也完全可以处理这些问题。当然,人是复杂的感情动物,好多东西还不能完全通过字面意思去理解。说一个不是很恰当的例子:约会中,女孩提问你觉得现在的房价如何。字面意思是房价,潜在意思是你的购房能力如何。 2.3 搜索引擎该这么处理 假设搜索引擎具有跟我们一样的大脑的话,那他处理问题的方式应该是这样的:
1、分析所查询的问题是检索关键词还是提问 2、结果分为三种, 答案已知直接输出结果;
途径已知,输入解决途径;
提供最符合用户预期的排序结果共用户挑选
3、不同的情况下会出现相互组合。当搜索引擎对关键词理解越充分时,结果越准确。 三、改进方法和策略 再总结一下用户的操作行为: 3.1 当用户输入的为关键词时: 1)已知用户的特征,根据其特征对搜索结果进行符合其本身的排序 2)未知用户特征,则视为普通的查询。提供结构话的搜索结果,即具有相关性的提示,相关性越高,结果越靠前。 3.2 当用户进行提问时: 1)分析提问的语义,简单的语义输出结果或途径 2) 无法分析确切的语义,提供多个结果给用户,同时根据用户的反馈不断调整结果。这也是用户特征的一部分。 3.3 搜索结果出现交叉时,痛痒还是需要参考用户的行为特征来对结果排序。 有几个名词,感兴趣的可再去搜索一下:Baidu-框计算;Google-知识图谱;Facebook-社交图谱搜索;Siri-语义搜索;概率-马尔可夫模型。 说白了,就是 搜索引擎对用户的搜索意图越理解,资料库越完备,输出的结果越精准。 还是举个例子来佐证一下:同样一个问题,好朋友的解答一般比陌生人要好,因为好朋友更了解你提问的动机,背景甚至期望得到的答案。 问题来了,计算机毕竟不是生物,他执行的仅仅是规则。能做的便是收集你的一些行为和特征来推断你的喜好: 1、个人信息:姓名、性别、籍贯、职业、行业、兴趣爱好、使用偏好等。 2、个人行为:搜索记录、浏览记录、社交行为等 3、处理方法:聚类、分类、数据挖掘 恩,其实是一个推荐引擎。更多知识和操作方法可以看一下Ibm Developer的文章:探索推荐引擎的秘密。 ———-分割线———— 本来想把推荐算法写一下的,查了一部分资料后发现自己还是了解的太少,还需要好好学习啊。未完待续。 (责任编辑:admin) |