|
在日常的网站运行和维护中,我们常常需要通过空间的www日志来了解蜘蛛的抓取情况,并对平时的工作作出调整,以下将一步一步的让你充分了解日志的设置方式以及蜘蛛的抓取特征分析让您充分了解每一个参数的含义并作为自己调整和修改的参考。 第一:需要确认自己的虚拟主机或者服务器开启了日志功能,一般的虚拟空间商的控制面板中都有www日志的记录功能,并提供站长们下载和分析,以下是编者使用的一个日志样式,因为每一个空间商不同其操作的顺序和方式不仅相同,此处仅作一个参考。 首先点击图一 或进入到图二中的界面,点击下载weblog日志就会出现图三 图四的界面,图四里面的每一个TXT都是以年-月-日来命名的,并且记录了日志的大小,点击查看就能看到详细的信息。
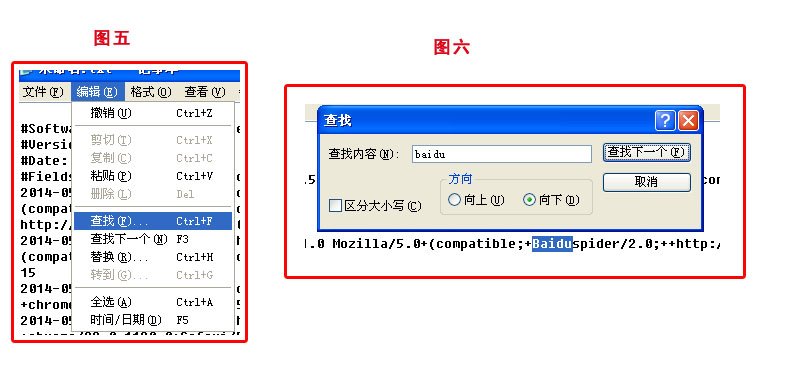
第二:在代码中查到蜘蛛的痕迹,因为一个TXT日志都是数百K,上千行,所以每条去检查是不现实的,我们需要充分了解蜘蛛的特征并通过查询功能快速的定位,因为蜘蛛的代码是spider,所以当检索spider时将出来所有的蜘蛛的来访情况,比如百度,google,360等等,而百度蜘蛛的特征是 baiduspider,我们这里着重讲解百度蜘蛛的情况。 我们先用记事本打开下载的TXT文档,并通过编辑查找功能(图五)来快速的检索,在检索框中输入baidu,并按确认就能找到百度蜘蛛的抓取代码(图六)
第三:找到百度蜘蛛的抓取行以后针对每一个参数,编者进行讲解并将对应的情况进行说明(参看示例图)。
参数1:这是百度蜘蛛来抓取内容的时间,这个时间一般和电脑时间相差8个小时,这主要是日志时间使用的是格林威治时间,与北京时间相差8小时;即您需要将时间加8小时才是对应的北京时间,所以参数1所示的蜘蛛来抓取的时间是 5月23日13时8分。 参数2:抓取内容的方式, GET表示抓取的意思后面紧接着的/index.html是被抓取的页面,这里表示蜘蛛来抓去了首页, 如果GET 后面是 /-- 则表示蜘蛛没有抓取任何东西,这时候需要引起网站维护人员的注意,你的内容或者是有问题,或者网站的首页布局,或者是内容文章等有问题,需要具体问题具体分析。 参数3:这个是蜘蛛来抓取内容时候服务器的IP地址,因为现在非常多的域名是使用CNAME的方式来解析的,所以很多站长根本都不知道自己的网站的IP是多少,而这个IP就是空间商让蜘蛛来抓取内容的IP,当你网站有问题时候可以通过查这一IP上的网站的个数与收录情况等来判断自己是否受到牵连。 参数4:这个参数是表示协议状态,通常200表示正常,404表示找不到文件,500表示内部服务器错误,一般网站所有页面都应该是200才正确,如果改版则一般会出现404错误,这里需要根据不同的返回值去查询具体的原因 题外话:每一位站长的新网站上线以后都在焦急的等待蜘蛛来抓取并索引,以让自己的网站有好的排名,但是现在的百度蜘蛛对于新网站的审查已经非常的严格而且时间一般都在20天以上,所以想要被百度蜘蛛来抓取内容和获得好的排名已经越来越困难,随着蜘蛛智能化程度越来越高,想通过蒙骗或者黑帽的手法来骗得蜘蛛的信任已经不太容易,而且即使得手了也会在百度的反作弊中心的后期对网站的深度检查中被发现并将作弊网站根据作弊程度做相应的顶格惩罚,所以奉劝站长们还是踏实做站,潜心做一个白帽高手,让你维护的企业网站排名无忧。 以上文章由四川硼酸在A 5首发,希望与所有的站长们一起共勉,如需转载请注明出处,谢谢合作。 (责任编辑:admin) |