|
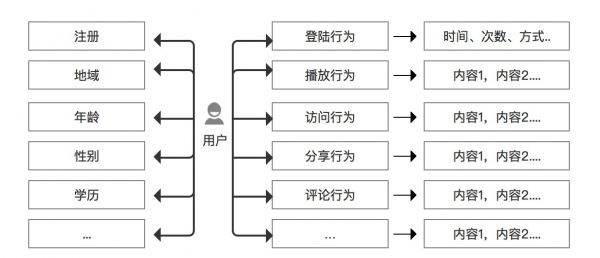
内容生产者,在上传内容时,对内容进行分类、设定内容标签。其内容进入后台首先按照用户上传时的分类进行筛选,之后由审核人员对其标签进行走查,将无分类的内容进行分类,同时对错误分类进行修正(此时所有审核人员的操作结果,系统都应该给生产者发送信息提示其内容被修改,优化上传流程)。所有人工审核后的内容库里的内容作为最终对外分发的结果,在前端对外分发。 至此,我们已经完成了对优质内容的筛选和对内容的聚类。那谁来消费我们的内容呢,谁来为我们的内容买单,我们的用户群是谁,他们来自哪?是男是女?年纪多大?他们是高、是矮,是胖,是瘦?从事什么工作?有什么爱好?他们收入如何? 二、用户篇(who) 承接上文,说到用户,绕不开的一个话题就是用户画像。要建立推荐系统的用户画像,我首先会问自己两个问题:“我们的用户是谁?”“他们都喜欢什么?”如果说用户画像是对一个人描述,那么第一个问题更像是描述一个人的外在,第二个问题更像是描述一个人的内在。外在对应用户属性,内在则对应用户行为,行为连接内容,从而分析用户喜好倾向,如下图所示:
此处数据统计的维度和准确性的重要性不再赘述,左侧是用户属性,右侧是相关的用户操作行为,所有的操作行为最终都能落地到具体一个内容上(我们在“内容篇”已经讲过如何对内容进行分类标识)我们通过看内容分类标识,从而分析用户的喜好倾向。 这种方法就好比我们写日记,记流水账,只要我们把足够多的信息记录下来,我们就能足以分析数这个人详细用户画像 例如:2017年5月12日,家住北京,24岁,清华大学毕业的姑娘小倩穿上她的adidas的衣服,开着她的奔驰车,去王府井的一家人均价位在100/位的火锅店吃火锅….),只要我们记录的信息足够多,足够精确,对用户画像的描述也就越清晰。 在推荐系统里,我们通过用户画像需要解决的是用户喜好倾向的问题,但用户的喜好倾向不是一成不变的,除了要做到数据的持续收集,在判定用户兴趣时,用户的短期兴趣倾向和长期兴趣倾向需要做策略的融合。持续对两种维度的权重调权,从而得到最优解。 举例:我是一个喜欢摇滚音乐的用户,不经意间听了几首纯音乐,我们并不能一刀切的认为用户的喜欢倾向由摇滚转为轻音乐,而是应该记录下这种行为,在策略里不断试探尝试用户兴趣,持续推荐不同内容,从而判定用户真正兴趣。 在推荐系统里,我们通过用户画像需要解决的是用户喜好倾向的问题,但用户的喜好倾向不是一成不变的,除了要做到数据的持续收集,在判定用户兴趣时,用户的短期兴趣倾向和长期兴趣倾向需要做策略的融合。持续对两种维度的权重调权,从而得到最优解。 举例:我是一个喜欢摇滚音乐的用户,不经意间听了几首纯音乐,我们并不能一刀切的认为用户的喜欢倾向由摇滚转为轻音乐,而是应该记录下这种行为,在策略里不断试探尝试用户兴趣,持续推荐不同内容,从而判定用户真正兴趣。 三、推荐篇(how) 解决了物的问题,又解决了人的问题,现在接下来的最后一步就是,我们如何把物交付到人的手中。 在做推荐之前,我们需要做的一件事就是:数据的收集、上报。不同于上述内容质量和用户画像的数据统计维度,应用于推荐的数据统计维度更多,是两者的超集,除此以外,一些操作系统、app版本、网络环境、用户操作访问路径的分析,漏斗的模型的转化….等等都与推荐行为息息相关。此处关于数据上报的维度需要针对不同平台,不同推荐业务,不同场景做具体问题具体分析。 关于一心想求推荐系统算法公式的同学,可以去抱算法工程师大腿了,此处不做详细罗列,只来聊聊我所理解的推荐的一些原理,毕竟产品经理的数学和算法工程师比起来,基本30分到40分水平…. 我把每个用户想象成一个独立的点,每个用户背后都带有各种各样的用户属性,我们把具有相同属性的用户之间建立一条连线,众多的用户其彼此间的连线也错综复杂,由此形成了一个独立的用户面。同样的原理,把每条内容也想成一个独立的点,每条内容背后也都带有各种各样的内容聚类标识,我们把具有相同类别的内容之间建立一条连线,众多的内容间的连线也错综复杂,由此形成了一个独立的内容面。 (责任编辑:admin) |