|
一段文本信息,它本身是一个由语言组成的字符串系列,本项技术点的主要任务是将一段连续的文本序列信息拆分成多个子序列。它与语言本身相关,面对不同的语言,处理文本的方式往往会不一样。对于中文,由于其语言多歧义且表意紧凑的特性,在实际应用中,一般需要借助NLP的相关技术对内容进行特征抽取,甚至人工标注等,生成对应的词典,随后再基于词典利用分词器进行分词,才能看到较好的文本词条效果。 而对于英文,普遍的英文句子,段落内容,它会以空格符作为单词之间的分隔符,所以一般情况下,以空格符对英文内容进行拆分,已经可以取得比较好的效果,不过英文中也会存在一些特殊模式,如带上撇号的格式——“Teacher’s office”,连字符格式——“English-speaking”,也需要进行对应的处理,把单词提取出来。 (2)停用词过滤 停用词是指在文档列表中出现的频数较高且价值不大的词。以英文为例,在英文文档中出现次数较多的停用词如:”is”、”the”、”I”、“and”、”me”等等;这一类词语在往往出现在所有文档中,若以此类词语为term进行索引构建,则会产生多个全量文档索引列表。停用词过滤的使用往往依赖于实际使用场景,关键字查询使用得较为频繁的场景如某一个电商品牌的垂直型搜索引擎,一个合适的停用词表显得尤为重要;而对于Web搜索引擎如百度、Google等,该类型的搜索引擎面向的查询场景较多,通用性较强,往往不需要停用词过滤。 (3)词条归一化 基于上述两点,将文档内容转换成一个或多个term后,在查询时,最理想的情况是用户输入的关键字刚好与term完全匹配,实际上,很多时候用户输入的query与词条之间往往不会完全匹配,而用户们还是希望query能与词条进行匹配,比如用户在查询“color”时,用户肯定也希望能看到关于“colour”的返回结果。词条归一化的任务就是将一些看起来不完全一致的词条划分为一个等价类,比如英式单词colour和美式单词color归为一类、Air-conditioner和airconditioner归为一类等等;这样,用户在查询时,只要对等价类中的任意单词进行搜索,都会返回包含等价类中的任意一个单词的文档。 (4)词干提取、词形还原 这是词条规范化的两种重要方式,用于扩展检索范围。词干提取的主要思想是“缩减”,将词条转化为词干,如:将“beaches”处理成“beach”, 将“bananas”处理成“banana”等;词形还原的主要思想是“转换”,如:将“doing”、“done”、“did”转化成原型“do”,将“given”、“gave”转化成原型“give”等;词干提取的实现方法一般是基于规则对词条后缀进行缩减,至于词形还原,其实现方法需要词典来进行词形变化的映射;基于在此结合词条归一化技术,对扩展检索范围会产生一定的正向作用。 3.2 倒排记录表的构建 倒排记录表的构建过程面向的是海量的文档数据集合,在大小规模上它比词项集合要大得多,无法完全存放在内存当中,需要写入磁盘。因此,在构建倒排记录表时我们有必要为内存的使用作考虑。
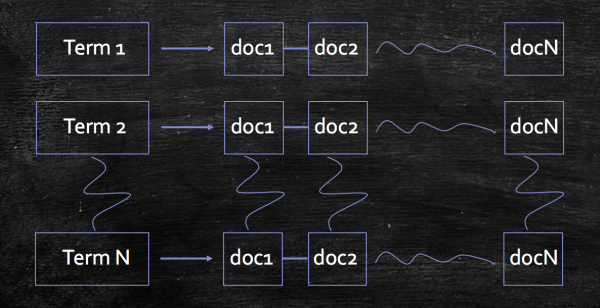
图3 倒排索引概念图 在无法全内存的情况下,倒排记录表的主要构建思想是“分割”,亦即基于一定的处理逻辑对全量文档集合进行等份的批量处理。对于不同的业务需求,构建倒排记录表的方法往往会不一样。基本的构建方法如下: S1: 通过一系列的处理将文档集合转化为“词项ID—文档ID”对;S2: 对词项ID、文档ID进行排序,将具有相同词项对文档ID归并到该词项所对应的倒排记录表中,效果如图3所示;S3: 将上述步骤产生的倒排索引写入磁盘,生成中间文件;S4: 将上述所有的中间文件合并成最终的倒排索引。 从业务应用场景的角度出发,倒排记录表的构建方法主要有:单遍扫描和多遍扫描;从工程角度出发,倒排记录表的构建方法主要有:分布式构建和动态构建。 3.2.1 单遍扫描构建 (责任编辑:admin) |