|
01.网页为何要去重? 对于搜索引擎来说,希望呈现给用户的是新颖且吸引人的内容,是高质量的文章,而不是大量的“换汤不换药”的套话;我们在做SEO优化,要进行内容编辑时,难免会参考其他同类的文章,而这篇文章或许被多人采集过,这就导致了网络上的相关信息大量的重复。 如果一个网站存在大量的恶劣采集内容,不仅会影响用户体验,还会造成搜索引擎直接屏蔽该网站。之后网站上的内容,蜘蛛再难抓取了。
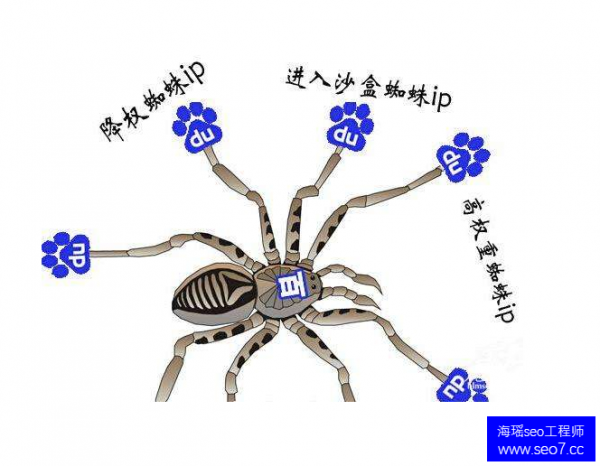
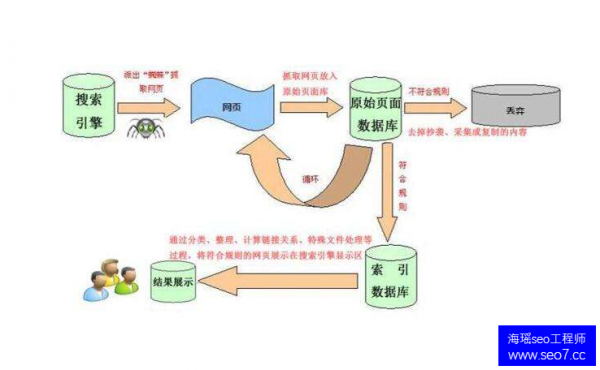
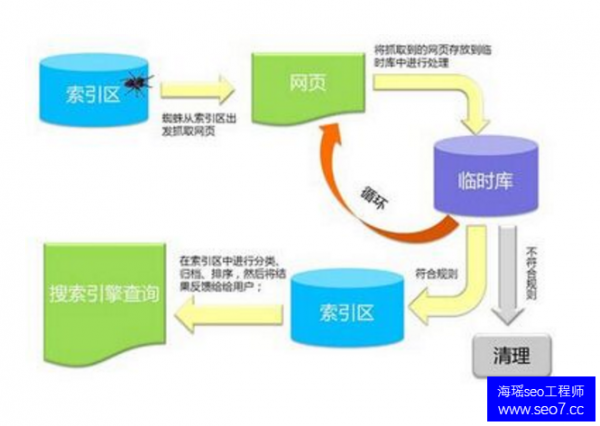
02.搜索引擎工作原理 搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。 搜索引擎的工作原理: 第一步:爬行 搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链接,像蜘蛛在蜘蛛网上爬行一样,所以被称为“蜘蛛”也被称为“机器人”。搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容。
第二步:抓取存储 搜索引擎是通过蜘蛛跟踪链接爬行到网页,并将爬行的数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步:预处理 搜索引擎将蜘蛛抓取回来的页面,进行各种步骤的预处理。 除了HTML 文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。 但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
第四步:排名 用户在搜索框输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程与用户直接互动的。但是,由于搜索引擎的数据量庞大,虽然能达到每日都有小的更新,但是一般情况搜索引擎的排名规则都是根据日、周、月阶段性不同幅度的更新。
03.网页去重的代表性方法 搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。 去重的工作一般在分词之后索引之前,搜索引擎会在页面已经分出的关键词中,提取部分具有代表性的关键词进行计算,从而得出一个该网站关键词的特征。 目前, 网页去重代表性方法有3种。 1)基于聚类的方法。该方法是基于网页文本内容以6763个汉字作为向量的基, 文本中某组或某个汉字所出现的频率就构成了代表网页的向量, 通过计算向量的夹角确定是否是相同的网页。 2)排除相同URL方法。各种元搜索引擎去重主要采用此方法。它分析来自不同搜索引擎的网页URL, URL 相同, 即被认为是相同的网页, 可将其去除。 3)基于特征码的方法。这种方法利用标点符号多数出现在网页文本的特点, 以句号两边各5 个汉字作为特征码来唯一地表示网页。 三种方法中,第一种和第三种大多数还是基于内容来判定,所以很多时SEO人员会通过伪原创工具来修改文章内容,但是很多时候伪原创工具会将原文改的不通顺,这样也不利于排名与收录。 也有网站利用搜索引擎的漏洞,比如权重高的网站进行恶劣采集,因为权重高的网站蜘蛛会优先抓取,所以这种做法会不利于一些权重低的网站。 (责任编辑:admin) |