|
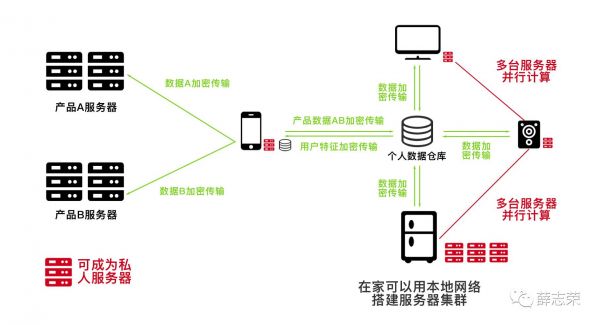
数据仓库最少包含身份信息、健康数据、兴趣爱好、工作信息、财产数据、信用度、消费信息、社交圈子、活动范围9个模块。每个模块相互独立,不耦合。 数据仓库包括用户特征、产品私有数据和共享数据。用户特征只有输出行为;私有数据只有输入行为;共享数据具有输入和输出行为。 模块间可以交换数据,模块具有规定的输入和输出接口格式。 每个模块内的机器学习算法可自行升级或替换成其他厂商提供的算法。 每个模块具有封闭性,算法不能向外发送用户数据。 每个模块拥有必选和非必须的固定数据字段。 产品可以向不同模块输入私有和共享数据。 产品提供的数据必须符合该模块的必选数据字段,可以额外提供非必选数据字段。 由模块内部的算法对该模块的共享、私有数据进行标注和建模,产出相关用户特征。 算法可以申请授权获取其他模块共享数据和用户特征。 在授权范围内,产品可以获取相关模块的用户特征和共享数据部分,无法访问私有数据。 数据仓库定期将数据加密备份至个人服务器。 数据仓库定期清理过期数据。 数据仓库容量不足时自动提醒用户备份数据并清理空间。 数据仓库自动加密用户数据,防止泄露。 不同厂商的数据仓库产品应该遵循以下协议: 不同数据仓库相同模块的必选数据字段需要一致。 数据仓库内部算法和数据仓应相互独立。 数据仓库可以沿用以往数据和用户特征。 数据仓库之间传输数据需要加密。 不允许设置后门。 数据仓库制定协议的好处: 企业可以根据规范制定数据仓库,降低被巨头控制的风险。 数据仓库内不同模块的机器学习算法可以由不同企业制定和替换。 有利于进行不同企业数据仓库之间的数据迁移和升级。 该用户名下的数据仓库进行数据同步时是加密的,降低隐私的曝光和风险。 人工智能需要考虑运算性能、电量、发热量、数据采集和人机交互等问题。在移动端,手机依然是人工智能助理的最好载体,可穿戴式设备更多成为辅助;在家或办公室里,最好的人工智能助手载体应该一分为二,一是可与用户对话交互的电器,例如现在流行的智能音箱,还有具有大屏展示的电视,甚至是24小时供电的路由器;另外一个是具有天生优势的冰箱:它也是24小时供电,它的自动降温能力能更好地解决复杂运算时所产生的热量问题,它的庞大体积可以容纳更多存储数据的硬盘和计算机部件。 可推测,冰箱将成为个人人工智能的运算中心,就像一台服务器;手机和智能音箱等将成为与用户打交道的人工智能助理。当运算中心处理完数据后,将结果同步至相关人工智能助理,数据仓库将成为连接它们的桥梁。只有完善底层的数据共享,人工智能才能发挥出最大价值。
以上就是第二章的内容,下一章为《人工智能时代下交互设计的改变》,敬请期待。 (责任编辑:admin) |