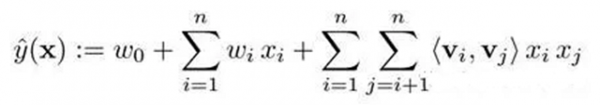|
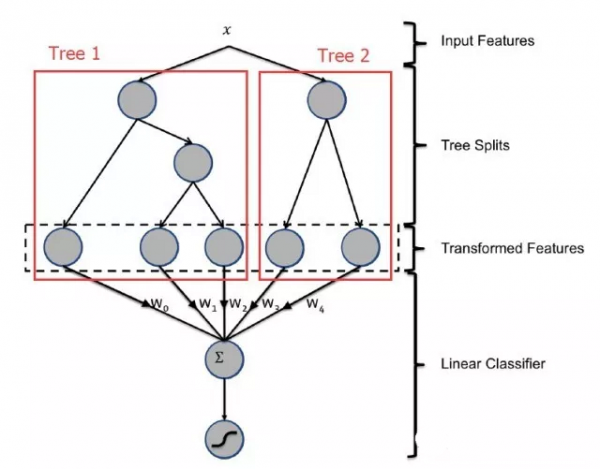
机器学习会按照优化目标求解最优解,如果优化目标有偏差,得到的模型也存在偏差,并且在迭代中模型会不断地向这个偏差的方向学习,偏差会更加严重。 我们的方法是给样本添加权重,并且将样本权重加到loss function中,使得优化目标与评测指标尽可能的一致,达到控制模型的目的。 LR是个线性分类模型,要求输入是线性独立特征。我们使用的稠密的特征(维度在几十到几百之间)往往都是非线性的,并且具有依赖性,因此需要对特征进行转换。 特征转换需要对特征的分布,特征与label的关系进行分析,然后采用合适的转换方法。我们用到的有以下几种:Polynomial Transformation,Logarithmic or Exponential Transformation,Interaction Transformation和Cumulative Distribution Function等。 虽然LR模型简单,解释性强,不过在特征逐渐增多的情况下,劣势也是显而易见的。 特征都需要人工进行转换为线性特征,十分消耗人力,并且质量不能保证 特征两两作Interaction 的情况下,模型预测复杂度是。在100维稠密特征的情况下,就会有组合出10000维的特征,复杂度高,增加特征困难 三个以上的特征进行Interaction 几乎是不可行的 中古时期 为了解决LR存在的上述问题,我们把模型升级为Facebook的GBDT+LR模型,模型结构如图所示。
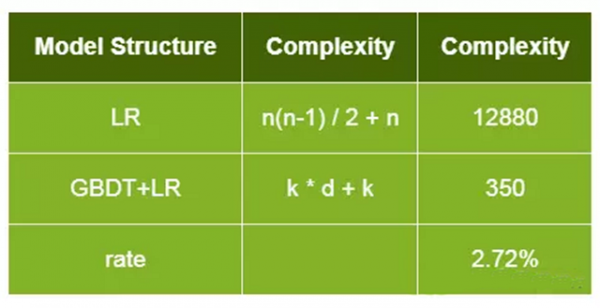
GBDT是基于Boosting 思想的ensemble模型,由多颗决策树组成,具有以下优点: 对输入特征的分布没有要求 根据熵增益自动进行特征转换、特征组合、特征选择和离散化,得到高维的组合特征,省去了人工转换的过程,并且支持了多个特征的Interaction 预测复杂度与特征个数无关 假设特征个数n=160决策数个数k=50,树的深度d=6,两代模型的预测复杂度对比如下,升级之后模型复杂度降低到原来的2.72%
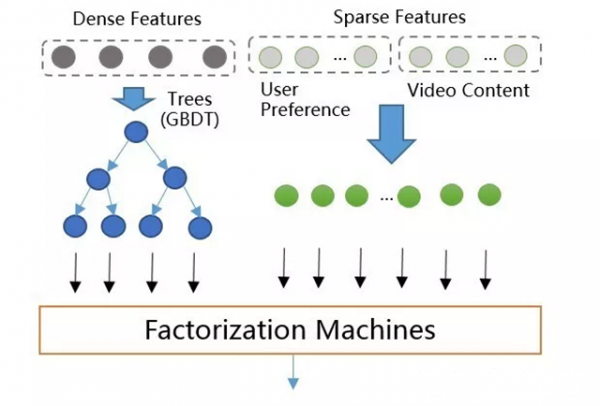
GBDT与LR的stacking模型相对于只用GBDT会有略微的提升,更大的好处是防止GBDT过拟合。升级为GBDT+LR后,线上效果提升了约5%,并且因为省去了对新特征进行人工转换的步骤,增加特征的迭代测试也更容易了。 近代历史 GBDT+LR排序模型中输入特征维度为几百维,都是稠密的通用特征。 这种特征的泛化能力良好,但是记忆能力比较差,所以需要增加高维的(百万维以上)内容特征来增强推荐的记忆能力,包括视频ID,标签,主题等特征。 GBDT是不支持高维稀疏特征的,如果将高维特征加到LR中,一方面需要人工组合高维特征,另一方面模型维度和计算复杂度会是O(N^2)级别的增长。所以设计了GBDT+FM的模型如图所示,采用Factorization Machines模型替换LR。
Factorization Machines(FM)模型如下所示,具有以下几个优点: 模型公式
前两项为一个线性模型,相当于LR模型的作用 第三项为一个二次交叉项,能够自动对特征进行交叉组合 通过增加隐向量,模型训练和预测的计算复杂度降为了O(N) 支持稀疏特征 这几个优点,使的GBDT+FM具有了良好的稀疏特征支持,FM使用GBDT的叶子结点和稀疏特征(内容特征)作为输入,模型结构示意图如下,GBDT+FM模型上线后相比GBDT+LR在各项指标的效果提升在4%~6%之间。 典型的FM模型中使用user id作为用户特征,这会导致模型维度迅速增大,并且只能覆盖部分热门用户,泛化能力比较差。在此我们使用用户的观看历史以及兴趣标签代替user id,降低了特征维度,并且因为用户兴趣是可以复用的,同时也提高了对应特征的泛化能力。 我们主要尝试使用了L-BFGS、SGD和FTRL(Follow-the-regularized-Leader)三种优化算法进行求解: SGD和L-BFGS效果相差不大,L-BFGS的效果与参数初始化关系紧密 FTRL,较SGD有以下优势: 带有L1正则,学习的特征更加稀疏 使用累计的梯度,加速收敛 根据特征在样本的出现频率确定该特征学习率,保证每个特征有充分的学习 (责任编辑:admin) |