|
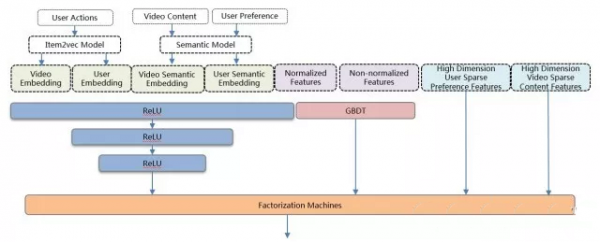
FM模型中的特征出现的频次相差很大,FTRL能够保证每个特征都能得到充分的学习,更适合稀疏特征。线上测试表明,在稀疏特征下FTRL比SGD有4.5%的效果提升。 当代模型 GBDT+FM模型,对embedding等具有结构信息的深度特征利用不充分,而深度学习(Deep Neural Network)能够对嵌入式(embedding)特征和普通稠密特征进行学习,抽取出深层信息,提高模型的准确性,并已经成功应用到众多机器学习领域。因此我们将DNN引入到排序模型中,提高排序整体质量。 DNN+GBDT+FM的ensemble模型架构如图所示,FM层作为模型的最后一层,即融合层,其输入由三部分组成:DNN的最后一层隐藏层、GBDT的输出叶子节点、高维稀疏特征。DNN+GBDT+FM的ensemble模型架构介绍如下所示,该模型上线后相对于GBDT+FM有4%的效果提升。
DNN模型 使用全连接网络,共三个隐藏层。 隐藏节点数目分别为1024,512和256。 预训练好的用户和视频的Embedding向量,包含基于用户行为以及基于语义内容的两种Embedding。 DNN能从具有良好数学分布的特征中抽取深层信息,比如embedding特征,归一化后统计特征等等。 虽然DNN并不要求特征必须归一化,不过测试发现有些特征因为outlier的波动范围过大,会导致DNN效果下降。 GBDT模型 单独进行训练,输入包含归一化和未归一化的稠密特征。 能处理未归一化的连续和离散特征。 能根据熵增益自动对输入特征进行离散和组合。 FM融合层 FM模型与DNN模型作为同一个网络同时训练。 将DNN特征,GBDT输出和稀疏特征进行融合并交叉。 使用分布式的TensorFlow进行训练 使用基于TensorFlow Serving的微服务进行在线预测 DNN+GBDT+FM的ensemble模型使用的是Adam优化器。Adam结合了The Adaptive Gradient Algorithm(AdaGrad)和Root Mean Square Propagation(RMSProp)算法。具有更优的收敛速率,每个变量有独自的下降步长,整体下降步长会根据当前梯度进行调节,能够适应带噪音的数据。实验测试了多种优化器,Adam的效果是最优的。 工业界DNN ranking现状 Youtube于2016年推出DNN排序算法。 上海交通大学和UCL于2016年推出Product-based Neural Network(PNN)网络进行用户点击预测。PNN相当于在DNN层做了特征交叉,我们的做法是把特征交叉交给FM去做,DNN专注于深层信息的提取。 Google于2016年推出Wide And Deep Model,这个也是我们当前模型的基础,在此基础上使用FM替换了Cross Feature LR,简化了计算复杂度,提高交叉的泛化能力。 阿里今年使用attention机制推出了Deep Interest Network(DIN)进行商品点击率预估,优化embedding向量的准确性,值得借鉴。 总结 推荐系统的排序是一个经典的机器学习场景,对于推荐结果影响也十分重大,除了对模型算法的精益求精之外,更需要对业务的特征,工程的架构,数据处理的细节和pipeline的流程进行仔细推敲和深入的优化。 Ranking引入DNN仅仅是个开始,后续还需要在模型架构,Embedding特征,多样性,冷启动和多目标学习中做更多的尝试,提供更准确,更人性化的推荐,优化用户体验。 (责任编辑:admin) |