|
立足场景,打磨技术工具,才是王道。
项目背景: 一家工厂请我的团队做咨询服务,说他们希望制作一个智能招聘的机器人程序。 因为他们有很多的工人招聘需求,而且工人的流动性很大,这就导致面试官应接不暇,虽然各个都面见,但是效果往往不好,难以摸清楚候选人的真实意图,而且基于工种的特殊性,又无法省略面试。 于是我们对他们的需求进行了调研,发现对于他们的工种呢,需要具备良好的语言表达能力,性格和善,而且学历要求不高,月薪资不能给超过4000元。 基于这些情况呢,我们分析了一下他们的具体场景,决定开发一款小程序来实现这个功能。 接下来我会尽量以业务方的视角去描述整个项目的思考逻辑,设计到底层NLP算法、问答模型、人机对话核心模块的知识点大家可以慢慢了解,主要可以体会这种场景和应用的思考思路。 项目开展:
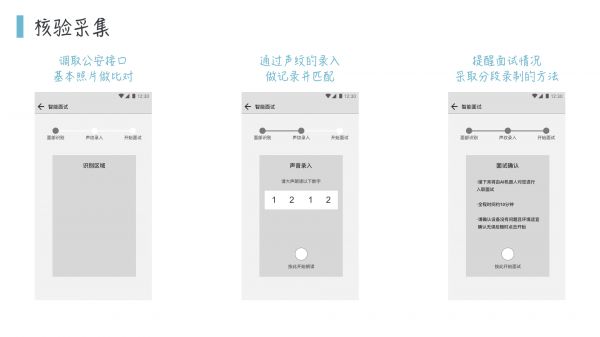
那么项目初期,我们分析了业务的具体需求,决定引入人脸识别和语义分析等技术,来实现他们的需求。那么对于初期来讲呢,在初步的机器学习水准上,是不可能完全替代真人的,所以我们考虑制作一个管理后台,把面试情况和结果展示给真人来做监督学习,给机器打分,从而让机器知道自己的得失从而去改进。
那么前端我们需要做一个小程序入口,来给新人做报名的动作,这里着重要验证新人的身份证号,这样做的目的是在面试环节,可以调用公安部门的接口拿到照片,从而通过人脸识别和基准照片的比对来验明正身。为什么不在报名的时候就直接做身份比对呢?首先虚拟面试环节是有替考可能的,所以需要校验,这里是考虑到有一些替他人报名的情况,而且造假动机不足,我们决定后置这个检验,减少初始流程压力,放更多的人进来。 那么其实还有一种做法,对于这种非紧急的情况,不同于视频网站的鉴黄流程,我们可以采取事后批判的手段,比如在入职的转正时,截取新人的虚拟面试图片n张,来确认是否是本人,如果不是本人,予以辞退或处罚。在这里考虑到担心法律纠纷的问题,选择在签订劳动合同之前完成人身的核验工作。 那么前后端的功能模块搭建好了之后,我们还需要一个支持图形存储的数据库,来将面试者的面试情况储存起来。 接下来我们就要设计一下,如何让机器学习介入这个流程。 第一步:收集初始学习资料 对于一个智能问答机器人的初始学习,是需要一定的问答量作为启动的,所以我们让线下面试官总结了一个500道题左右的题库和问答样例,作为机器学习的初始学习资料,但是并不意味着机器通过对这些问题和答案的深度学习可以达到面试官的标准,我们还需要模拟几个面试者来对机器人进行初步的检测和完善,所以我们在我们认知范围内,又和机器人进行了数十轮的对话演练。 第二步:监督式学习 在机器人实际投入工作的过程中,我们发现情况有些复杂。通过之前业务给我们的信息,我们评估决定用问答式机器人即可,即类似于智能的FAQ,只要做基本的语义意图分析即可。比如,「我缺钱」、「我没钱」、「我想要钱」我们都可以将它记录为「我要借钱」,这时推送信用卡办卡链接即可。 但是实际应用的过程中,实际场景其实是流程化和多变的。比如,机器在第一阶段的任务其实是挖掘到面试者的入职意愿,但是这个过程并不是我们想象的「你想要这份工作吗」「是的」这么简单的,我们需要听取求职者的更多信息,比如机器需要再继续追问2到3个问题,询问面试者对于「通勤时间长」「你的爱好」等,来佐证这个事实。在完成了第一阶段对于入职意愿的判断,才能进入第二阶段,进行对客观条件是否符合的考量。 还有一部分复杂的情况是,如果机器问了「你叫什么名字」,而面试者回答「我是小芳,今年20岁」,那么下一个问题如果是正常人类的话,就不会问「你年龄多少」了。但是机器往往会忽略到除了目标信息之外的其它信息,所以这一点上也需要一定的训练去把信息有效地吸收提取,如果机器认为「20岁」这个概念没有明确的话,他会追问「您今年20岁吗」,这样面试者即可确认。 第三步:评价模型介入
|