|
一、 技术理想化 每种数据收集方式都有其独特的技术优势,但没有一种收集方式能完美的捕获到访问者在网站上的所有动作,每种技术也都会由于自身的局限性导致你看到的数据是并不完美的数据。以计算页面停留时间为例,下图是一次访问的时间记录:(图示中时间皆为进入页面的时刻)
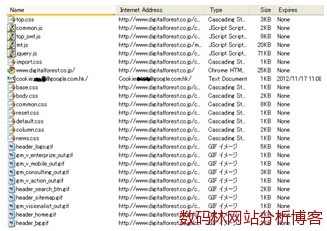
通常计算页面停留时间的方法为:当前页面的进入时刻与下一页面的进入时刻差。由此得知上例中页面的停留分别如下: 页面A:5分钟 页面B:1分钟 页面C:4分钟 页面D:? 为什么页面D的停留时间没有?没错,无论哪种收集方式都无法捕捉到页面D的准确停留时间,原因很简单,这些数据收集方式都无法捕捉到访问者离开的时刻(或者在退出页停留了半天没做任何点击,或者直接关闭了浏览器)。所以不同的工具厂商对退出页的停留时间有不同的定义,有的统一计算为1分钟,有的干脆认为是0分钟。 目前主要有下面几种技术或限制数据的获取,或混淆现有收集到的数据。 1. 缓存 这里说的缓存不是指物理芯片例如CPU的缓存,而是为了节约网络资源,提高浏览网页速度建立的浏览器缓存或代理服务器缓存。简单的理解这两种缓存就是,将曾经访问过的网页内容(包括图片以及cookie文件等)存放在电脑或代理服务器里。当你调用以前阅读过的页面时,可以直接调出缓存中的内容,而不需要再次从网站服务器上重新传送数据。 下图就是访问一个网站后本地缓存文件夹中留下的文件记录:
由于当访问者通过本地缓存访问网站时,并不会往网站服务器发送请求,服务器中自然也就不存在这次访问的Log记录。也就是说通过Web日志收集到的数据一定会丢失这部分流量。 2. 网络爬虫 如果想要讲清搜索引擎爬虫的原理和算法恐怕单开一个章节都不够,而且也不是这本书关注的内容,所以这里就不再赘述。 下面先给出一条网站服务器Log中的搜索引擎爬虫记录: 203.208.60.178 [10/Nov/2011:12:00:00 +0800] "-" "GET /index.php HTTP/1.1" 200 30000 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +)" 从上面log记录可以看出:2011年11月10日 12:00:00的时刻,Google的Googlebot(Google的搜索引擎爬虫名)到访并抓取了首页/index.php。 这意味着Web日志收集的数据中会混有这部分数据。同时需要提醒的是,爬虫对网站服务器的造访仅仅为了下载抓取主要信息,网页内容并不会像网友访问时在浏览器里得以展示;换句话说,也就是此时网页源代码里的JavaScript数据收集代码是无法执行的。 3. 防火墙 由于防火墙的原理机制比较复杂,这里就不做详细解释,有兴趣的可以从维基百科或别的资源了解。 简单的理解防火墙功能,可以认为它就是在网络中根据信任程度的高低,控制来回传送的数据流。它就像一张过滤网时刻监督过滤试图通过它的数据流。
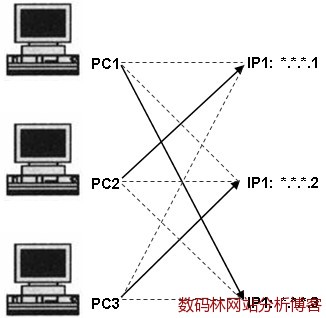
防火墙给网络带来安全的同时可能会阻止JavaScript脚本向数据收集服务器发送数据。这无疑又会使JavaScript标记丢失一部分流量。 二、 访问者理想化 网站分析主要为了跟踪访问者在网站上的行动,但往往又被访问者对个人电脑的行为所影响。也许这就是理想与现实的差距,因为你不能要求所有的网友都按照你想要的方式在网上遨游。 1. IP设置 Web日志收集数据时主要依靠访问者的IP来区分唯一访问者,但当下面这种动态的IP分配方式出现时收集的数据出现误差就难免了。
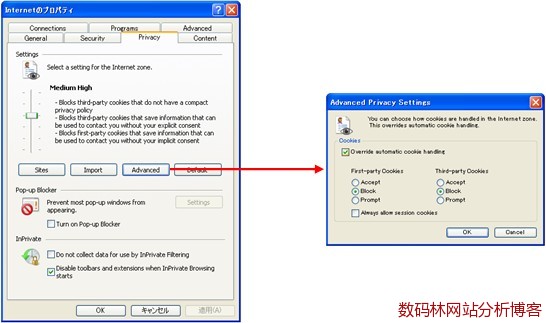
一台机器使用不同的IP很可能会造成统计到的访问者要比实际的多。可以看出网站分析工具统计出的其实并不是真实的访问者人数,只不过是一个个IP或一个个浏览器罢了。所以更不用说当多个人使用同一台电脑时能否被正确统计了。 2. JavaScript有效设置 有些访问者为了确保安全可能会选择关闭浏览器里的JavaScript有效设置,这样失去的不止是一些网页特效;对采用JavaScript标记的工具商来说,失去的还有这部分访问者在目标网站上的所有行动记录。 3. Cookie设置 (1)禁用Cookie 互联网的普及将人们带进全面的信息化社会,人们对个人信息的保护意识也逐渐强化起来。因为对隐私信息的敏感,一些人会选择禁用Cookie。
(上图可以看出Cookie的设置可以分为第一方Cookie和第三方Cookie两种设置,至于两种Cookie的区别有兴趣的可以查阅网上资料) 离开Cookie,采用JavaScript标记将无法区分访问次数和唯一身份访问者人数,没有这两个基本度量,网站分析能做的也就不多了。所以说,Cookie的禁用对JavaScript标记收集数据是一个巨大打击。 (2)删除Cookie 人们经常会为了信息保护等原因删除Cookie。
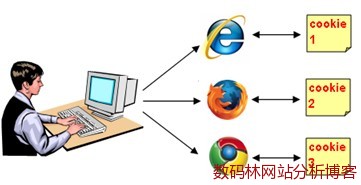
定期或不定期删除Cookie直接会导致唯一身份访问者人数比实际人数要多。因为如果Cookie删除后会被重建一个新的Cookie,这样对同一个访问者会被重复统计。 (3)多浏览器 即使是同一网站也会根据浏览器的不同在同一台电脑中设立不同的Cookie。
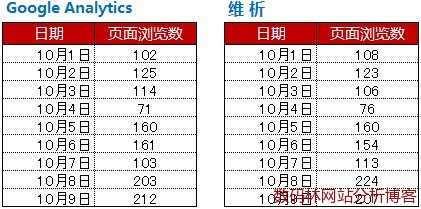
从上图能看出当同一个访问者使用了三种不同的浏览器访问网站时,JavaScript标记会由于Cookie的不同将这一个人统计成三个人。 面对看似如此糟糕的数据,我们能采取哪些措施规避误差数据带来的分析误区呢? 三、如何面对不完美的数据 前面的讨论中可以看出不仅不同的数据收集方式对统计结果有直接影响,很多技术因素和认为因素也会对统计结果产生各种影响。面对如此“糟糕”的数据,如何才能从中洞察到指引行动的方针呢? 先来看下某段时间内Google Analytics统计和维析的统计结果
(注:以上报表只是为简单说明并非真实,数据与格式皆为虚构) (责任编辑:admin) |