|
“我很好奇他们在搜什么?为什么他们不用谷歌或者雅虎图片,反而用我们的网站?”两个疑问引出一个新方向的诞生。 (FC本系列文章旨在探索那些能改变公司命运,从而带领公司走向巨大成功的重大决定)
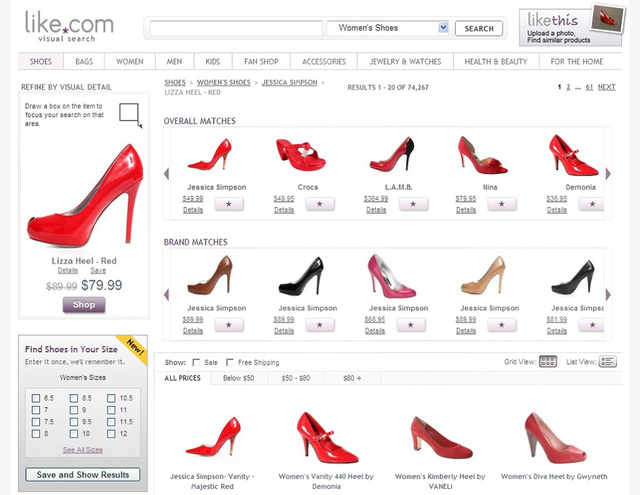
Riya.com确实曾是一颗冉冉升起的新星。 赫赫有名的风险资本家们,如Bay Partner以及Leapfrog Ventures,向该公司投入了1950万美金,共同创始人Burak Gokturk在技术领域也是游刃有余: 他是斯坦福的博士,同时还是一位图像识别方面的专家,名下有一打还多的专利。 2005年,当这家面部识别公司被谷歌收购的传言四起时,其产品不过才刚刚过了初步测试阶段。 “对于谷歌收购的流言,业内知情人士都缄口不言.......不过很明显,现在关于这家公司也是众说纷纭,”在Riya于TechCrunch的Michael Arrington家后院举办完酒会发布会派对后,Michael在博客上写道。 Riya承诺:通过摈弃对元数据的需要,并真正实现对照片中人脸和物体的识别,来自动化图像搜索的过程。2005年的时候,电脑就已经可以毫不费力的精细搜索文本了,但是如果要它们辨识分析一张照片中都有什么,它们只会呆若木“机”。 谷歌试图用游戏化的方式来解决自身的图片搜索问题:用户们可以用文字描述图片中的影像,这样谷歌搜索引擎就会从关键词中筛选信息而后在屏幕上显示出相关的图片。Riya(即之后的Like.com)的创始人认为将会有很多人希望在图片中圈出他们的朋友或者其他的东西,如此就可以更方便把图片整理纳入图片库。公司可以借此累积一个源于用户的不存在版权问题的图片数据库,再通过这些数据向用户售卖广告。 Riya.com的界面 他们都错了 这套系统过于复杂,一个包含五个步骤的程序,其中还有两个分支。而其商业计划又建立于太多的假设上—— “之后会是怎样,然后会怎样,而后又会怎样.......再之后我们就会开始赚到钱了,不过这样确实会有些曲折。”CEO Munjal Shah在2009年的一次谈话中如此评价道。Riya在刚刚发布一年之后就需要一个新的战略。 2006年4月25日,刚过午夜,Shah正在查看Riya的数据统计,随后他注意到每当一个人在上传私人照片并且圈图时,同时会有另外20个人在使用Riya搜索。他马上发了封邮件给其中一个共同创始人Gokturk,并在5分钟内就得到了回复。“我很好奇他们在搜什么?”Gokturk回道。 “为什么他们不用谷歌或者雅虎图片,反而用我们的网站?” 很快谜底揭开了。Riya并不是Flicker或者Y!Photos的代替品,它已经成为了网络上一个专门用来搜索图片的引擎。人们用他们的行动证实了他们需要一个专门用来搜索图片的引擎,一个比谷歌图片搜索更智能的引擎。 Riya很快就变身成Like.com,同时也成为了一个虚拟的鞋子包包手表珠宝的购物引擎,至此发起了对另一个领域的进攻。这项对Riya技术的重复利用使得用户可以寻找一张图片,比如一张系带红鞋的图片,然后用Like.com做一个“相似搜索”来找到相似的物品。用户可以找到多样化的产品,有不同的颜色,选购同明星相似的衣着,还可以上传他们自己最喜欢的物件,然后再搜索相似的物件。
Like.com 借助Riya这次的华丽变身,Shah和他的团队从投资者手中筹集到了额外的5000万美金。公司的年度收益达到了2000万,这一切都只是通过一个简单直接的过程:顾客浏览商品、点击、直接跳转到零售网站如亚马逊和Zappos.com,其后Like.com就会获得5%到15%的佣金。截至2009年,Like.com已经通过此举从商家手中获取到1亿美金的利润。 2010年,谷歌花了1亿美金收购并聘用了打造出这个引擎的团队,并关闭了这项服务。这也从另一个侧面说明了它与Like.com的近似程度(或者说被后者威胁到的程度 )。毋须说,如果几近失败的Like.com之前没这个华丽的转型的话,他们不会有这样的一个结局。 (via FC) (责任编辑:admin) |