|
被回复数,点赞数,评论内容长度,用户活跃度,用户关注、粉丝数、以及评论发布时间都将被作为参考指标。评论排序策略可应用的数据指标更加丰富。
对189条评论的前20条评论信息各项指标进行分析比对,发现随机性非常强。 推测此时评论显示排列策略不在考察各项数据指标,可能是利用评论分词处理后,与文章标签做比对哦,或算法筛选出用户更想看到的评论内容,或能够引起用户共鸣的评论前置。 结合头条的理念就是应该把用户“想看的评论”展示给用户,最好是能做到“你看到的就是你想说的”。头条在对评论进行排序的时候可能考虑了以下几点: 让评论的排序也“千人千面”,用户最先看到的评论应该是用户最感兴趣的; 要实现第1点,头条可以根据评论得到的赞的个数和评论者和阅读用户的相似程度,给评论赋予不同的排序权重; 在这一点上,很多之前的分析文章都会把评论排序盲目的分类,比如按照赞的多少,按照发布时间,顺序倒序等等。但实际上,目前用户量相对比较大的新闻、门户、聚合信息平台,都已经应用了最新的评论排序算法。 说到这里就不得不提高reddit,这款国外鼎鼎大名的新闻社交产品。他的评论排序策略重新定义了产品的评论区。
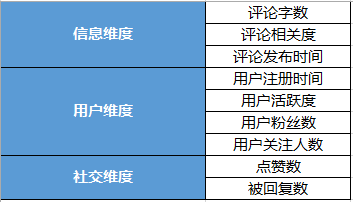
Reddit评论排序分析 “Best”排序 有人对评论like,则数据库会进行采集,评论越多,like的越多,则机器越能精确判定该评论的排名。通过对精确程度的量化,从用户的like中尽可能推算出评论真实质量。 机器从like与dislike数据库中抽样统计,计算出置信区间,我们第一步对这些区间进行排名,这个暂时排名比较的是这些评论最终排名100在一百次统计中95次可能落在的区间。 对于抽样数据需要在数量上有保证,不然系统仍然会将其排在低位。 10like+1dislike are better than 50like+25dislike. 前者会排在后者前面,通过概率计算结果来推算。 但问题是,Reddit的评论排序策略虽然可以有效的筛选出用户喜欢的评论,但对时间参数的过度重视,依然会让其他用户只将关注焦点放在最新的评论上,使得评论的长尾越来越长。 但回顾评论排序的算法历史,几乎都经历过按照发布时间到按照赞数,再到综合时间与赞数,再到现在综合多个参数进行综合考量。但其实回归本质及需求,都是为了解决下面这些问题: 赞数多的评论只是迎合了大部分用户的偏好,而没实际意义。 排名高的评论与文章并不相关,但因为一些手段和马太效应,更好的回答没得到足够的展示机会,于是被埋没。 有争议的问题,很难明确怎样的排序是公平的。 其实可以用作权重factor的无非以下几种,被回复数,点赞数,评论内容长度,用户活跃度,用户关注、粉丝数、以及评论发布时间。如何合理分配权重,是每个平台都会面对的问题,各自也有自己的策略。主要分为以下三个维度:
3.几点思考 除了今日头条之外的其他平台,可能将权重factor更加侧重于在信息维度,即评论字数,即评论相关度。但通过对头条评论排序靠前的用户的分析,我认为头条将权重factor更加侧重在了用户维度与社交维度。 首先,在社交维度上,被回复数高的评论拥有更高的排序权重,因为这样的评论能够激发话题,启动用户之间的互动。与此相比,被点赞数成了次级别的权重factor。因为确实存在这样的评论,用户点赞几千条,但是被回复数寥寥无几。 能够引起用户激烈互动行为的评论一定是好评论,但不是所有的好评论都能激发用户的讨论行为。 (责任编辑:admin) |