|
还有一种也可以算作反爬虫策略的就是异步数据,随着对爬虫的逐渐深入(明明是网站的更新换代!),异步加载是一定会遇见的问题,解决方式依然是F12。以不愿透露姓名的网易云音乐网站为例,右键打开源代码后,尝试搜索一下评论
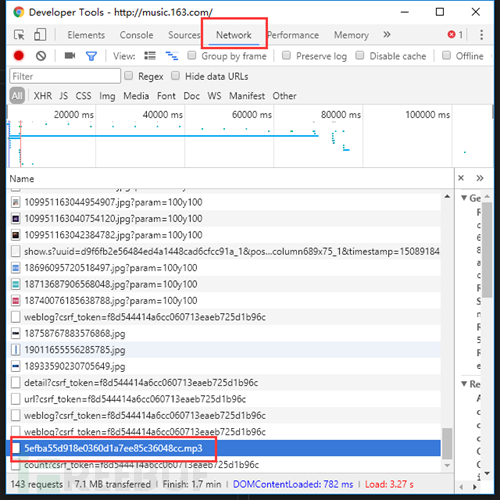
数据呢?!这就是JS和Ajax兴起之后异步加载的特点。但是打开F12,切换到NetWork选项卡,刷新一下页面,仔细寻找,没有秘密。
哦,对了 如果你在听歌的话,点进去还能下载呢…
仅为对网站结构的科普,请自觉抵制盗版,保护版权,保护原创者利益。 如果说这个网站限制的你死死的,怎么办?我们还有最后一计,一个强无敌的组合:selenium + PhantomJs 这一对组合非常强力,可以完美模拟浏览器行为,具体的用法自行百度,并不推荐这种办法,很笨重,此处仅作为科普。 总结 本文主要讨论了部分常见的反爬虫策略(主要是我遇见过的(耸肩))。主要包括 HTTP请求头,验证码识别,IP代理池,异步加载几个方面,介绍了一些简单方法(太难的不会!),以Python为主。希望能给初入门的你引上一条路。 (责任编辑:admin) |