|
模型的训练上,头条系大部分推荐产品采用实时训练。实时训练省资源并且反馈快,这对信息流产品非常重要。用户需要行为信息可以被模型快速捕捉并反馈至下一刷的推荐效果。我们线上目前基于storm集群实时处理样本数据,包括点击、展现、收藏、分享等动作类型。模型参数服务器是内部开发的一套高性能的系统,因为头条数据规模增长太快,类似的开源系统稳定性和性能无法满足,而我们自研的系统底层做了很多针对性的优化,提供了完善运维工具,更适配现有的业务场景。 目前,头条的推荐算法模型在世界范围内也是比较大的,包含几百亿原始特征和数十亿向量特征。整体的训练过程是线上服务器记录实时特征,导入到Kafka文件队列中,然后进一步导入Storm集群消费Kafka数据,客户端回传推荐的label构造训练样本,随后根据最新样本进行在线训练更新模型参数,最终线上模型得到更新。这个过程中主要的延迟在用户的动作反馈延时,因为文章推荐后用户不一定马上看,不考虑这部分时间,整个系统是几乎实时的。
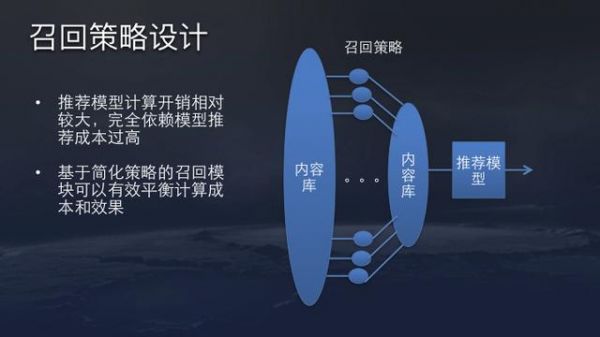
但因为头条目前的内容量非常大,加上小视频内容有千万级别,推荐系统不可能所有内容全部由模型预估。所以需要设计一些召回策略,每次推荐时从海量内容中筛选出千级别的内容库。召回策略最重要的要求是性能要极致,一般超时不能超过50毫秒。
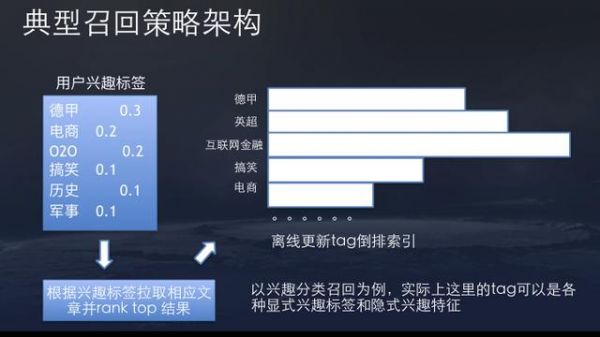
召回策略种类有很多,我们主要用的是倒排的思路。离线维护一个倒排,这个倒排的key可以是分类,topic,实体,来源等,排序考虑热度、新鲜度、动作等。线上召回可以迅速从倒排中根据用户兴趣标签对内容做截断,高效的从很大的内容库中筛选比较靠谱的一小部分内容。
二、内容分析 内容分析包括文本分析,图片分析和视频分析。头条一开始主要做资讯,今天我们主要讲一下文本分析。文本分析在推荐系统中一个很重要的作用是用户兴趣建模。没有内容及文本标签,无法得到用户兴趣标签。举个例子,只有知道文章标签是互联网,用户看了互联网标签的文章,才能知道用户有互联网标签,其他关键词也一样。
另一方面,文本内容的标签可以直接帮助推荐特征,比如魅族的内容可以推荐给关注魅族的用户,这是用户标签的匹配。如果某段时间推荐主频道效果不理想,出现推荐窄化,用户会发现到具体的频道推荐(如科技、体育、娱乐、军事等)中阅读后,再回主feed,推荐效果会更好。因为整个模型是打通的,子频道探索空间较小,更容易满足用户需求。只通过单一信道反馈提高推荐准确率难度会比较大,子频道做的好很重要。而这也需要好的内容分析。
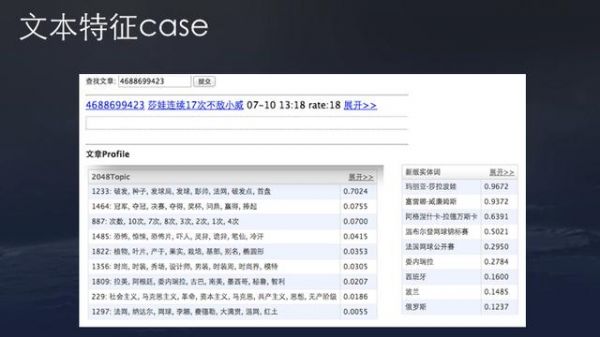
上图是今日头条的一个实际文本case。可以看到,这篇文章有分类、关键词、topic、实体词等文本特征。当然不是没有文本特征,推荐系统就不能工作,推荐系统最早期应用在Amazon,甚至沃尔玛时代就有,包括Netfilx做视频推荐也没有文本特征直接协同过滤推荐。但对资讯类产品而言,大部分是消费当天内容,没有文本特征新内容冷启动非常困难,协同类特征无法解决文章冷启动问题。
今日头条推荐系统主要抽取的文本特征包括以下几类。首先是语义标签类特征,显式为文章打上语义标签。这部分标签是由人定义的特征,每个标签有明确的意义,标签体系是预定义的。此外还有隐式语义特征,主要是topic特征和关键词特征,其中topic特征是对于词概率分布的描述,无明确意义;而关键词特征会基于一些统一特征描述,无明确集合。
|