|
实验过程中用户动作会被搜集,基本上是准实时,每小时都可以看到。但因为小时数据有波动,通常是以天为时间节点来看。动作搜集后会有日志处理、分布式统计、写入数据库,非常便捷。
在这个系统下工程师只需要设置流量需求、实验时间、定义特殊过滤条件,自定义实验组ID。系统可以自动生成:实验数据对比、实验数据置信度、实验结论总结以及实验优化建议。
当然,只有实验平台是远远不够的。线上实验平台只能通过数据指标变化推测用户体验的变化,但数据指标和用户体验存在差异,很多指标不能完全量化。很多改进仍然要通过人工分析,重大改进需要人工评估二次确认。 五、内容安全
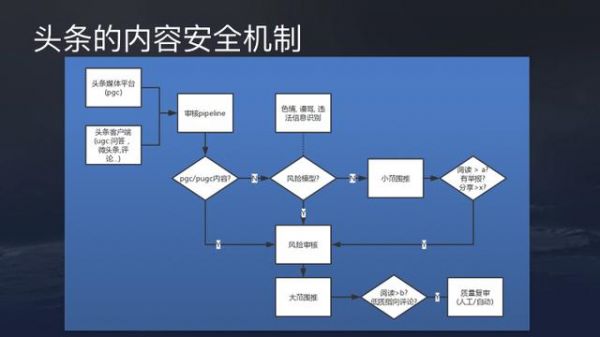
最后要介绍今日头条在内容安全上的一些举措。头条现在已经是国内最大的内容创作与分发凭条,必须越来越重视社会责任和行业领导者的责任。如果1%的推荐内容出现问题,就会产生较大的影响。 因此头条从创立伊始就把内容安全放在公司最高优先级队列。成立之初,已经专门设有审核团队负责内容安全。当时研发所有客户端、后端、算法的同学一共才不到40人,头条非常重视内容审核。
现在,今日头条的内容主要来源于两部分,一是具有成熟内容生产能力的PGC平台 一是UGC用户内容,如问答、用户评论、微头条。这两部分内容需要通过统一的审核机制。如果是数量相对少的PGC内容,会直接进行风险审核,没有问题会大范围推荐。UGC内容需要经过一个风险模型的过滤,有问题的会进入二次风险审核。审核通过后,内容会被真正进行推荐。这时如果收到一定量以上的评论或者举报负向反馈,还会再回到复审环节,有问题直接下架。整个机制相对而言比较健全,作为行业领先者,在内容安全上,今日头条一直用最高的标准要求自己。
分享内容识别技术主要鉴黄模型,谩骂模型以及低俗模型。今日头条的低俗模型通过深度学习算法训练,样本库非常大,图片、文本同时分析。这部分模型更注重召回率,准确率甚至可以牺牲一些。谩骂模型的样本库同样超过百万,召回率高达95%+,准确率80%+。如果用户经常出言不讳或者不当的评论,我们有一些惩罚机制。
泛低质识别涉及的情况非常多,像假新闻、黑稿、题文不符、标题党、内容质量低等等,这部分内容由机器理解是非常难的,需要大量反馈信息,包括其他样本信息比对。目前低质模型的准确率和召回率都不是特别高,还需要结合人工复审,将阈值提高。目前最终的召回已达到95%,这部分其实还有非常多的工作可以做。头条人工智能实验室李航老师目前也在和密歇根大学共建科研项目,设立谣言识别平台。 以上是头条推荐系统的原理分享,希望未来得到更多的建议,帮助我们更好改进工作。 作者:曹欢欢博士,今日头条资深算法架构师 来源:https://www.toutiao.com/i6511211182064402951/?tt_from=weixin_moments&utm_campaign=client_share&from=singlemessage×tamp=1516076329&app=news_article&utm_source=weixin_moments&isappinstalled=0&iid=23491847049&utm_medium=toutiao_ios&wxshare_count=11&pbid=6511586584332518916 题图来自unsplash,基于CC0协议 (责任编辑:admin) |