|
另外文本相似度特征也非常重要。在头条,曾经用户反馈最大的问题之一就是为什么总推荐重复的内容。这个问题的难点在于,每个人对重复的定义不一样。举个例子,有人觉得这篇讲皇马和巴萨的文章,昨天已经看过类似内容,今天还说这两个队那就是重复。但对于一个重度球迷而言,尤其是巴萨的球迷,恨不得所有报道都看一遍。解决这一问题需要根据判断相似文章的主题、行文、主体等内容,根据这些特征做线上策略。 同样,还有时空特征,分析内容的发生地点以及时效性。比如武汉限行的事情推给北京用户可能就没有意义。最后还要考虑质量相关特征,判断内容是否低俗,*情,是否是软文,鸡汤?
上图是头条语义标签的特征和使用场景。他们之间层级不同,要求不同。
分类的目标是覆盖全面,希望每篇内容每段视频都有分类;而实体体系要求精准,相同名字或内容要能明确区分究竟指代哪一个人或物,但不用覆盖很全。概念体系则负责解决比较精确又属于抽象概念的语义。这是我们最初的分类,实践中发现分类和概念在技术上能互用,后来统一用了一套技术架构。
目前,隐式语义特征已经可以很好的帮助推荐,而语义标签需要持续标注,新名词新概念不断出现,标注也要不断迭代。其做好的难度和资源投入要远大于隐式语义特征,那为什么还需要语义标签?有一些产品上的需要,比如频道需要有明确定义的分类内容和容易理解的文本标签体系。语义标签的效果是检查一个公司NLP技术水平的试金石。
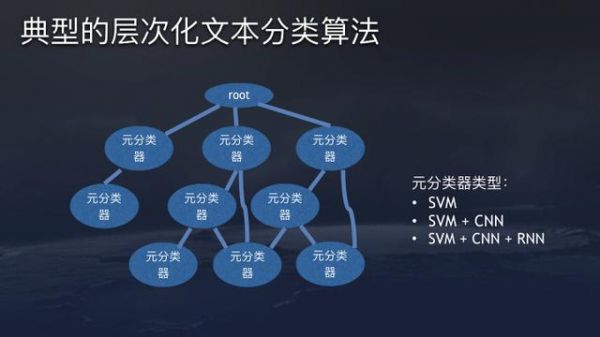
今日头条推荐系统的线上分类采用典型的层次化文本分类算法。最上面Root,下面第一层的分类是像科技、体育、财经、娱乐,体育这样的大类,再下面细分足球、篮球、乒乓球、网球、田径、游泳…,足球再细分国际足球、中国足球,中国足球又细分中甲、中超、国家队…,相比单独的分类器,利用层次化文本分类算法能更好地解决数据倾斜的问题。有一些例外是,如果要提高召回,可以看到我们连接了一些飞线。这套架构通用,但根据不同的问题难度,每个元分类器可以异构,像有些分类SVM效果很好,有些要结合CNN,有些要结合RNN再处理一下。
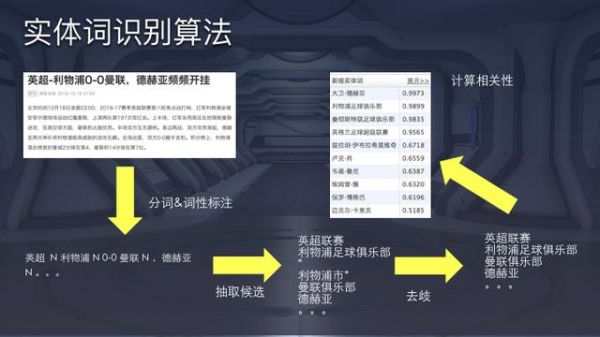
上图是一个实体词识别算法的case。基于分词结果和词性标注选取候选,期间可能需要根据知识库做一些拼接,有些实体是几个词的组合,要确定哪几个词结合在一起能映射实体的描述。如果结果映射多个实体还要通过词向量、topic分布甚至词频本身等去歧,最后计算一个相关性模型。 三、用户标签 内容分析和用户标签是推荐系统的两大基石。内容分析涉及到机器学习的内容多一些,相比而言,用户标签工程挑战更大。
今日头条常用的用户标签包括用户感兴趣的类别和主题、关键词、来源、基于兴趣的用户聚类以及各种垂直兴趣特征(车型,体育球队,股票等)。还有性别、年龄、地点等信息。性别信息通过用户第三方社交账号登录得到。年龄信息通常由模型预测,通过机型、阅读时间分布等预估。常驻地点来自用户授权访问位置信息,在位置信息的基础上通过传统聚类的方法拿到常驻点。常驻点结合其他信息,可以推测用户的工作地点、出差地点、旅游地点。这些用户标签非常有助于推荐。
当然最简单的用户标签是浏览过的内容标签。但这里涉及到一些数据处理策略。主要包括: 一、过滤噪声。通过停留时间短的点击,过滤标题党。 二、热点惩罚。对用户在一些热门文章(如前段时间PG One的新闻)上的动作做降权处理。理论上,传播范围较大的内容,置信度会下降。 三、时间衰减。用户兴趣会发生偏移,因此策略更偏向新的用户行为。因此,随着用户动作的增加,老的特征权重会随时间衰减,新动作贡献的特征权重会更大。 (责任编辑:admin) |