|
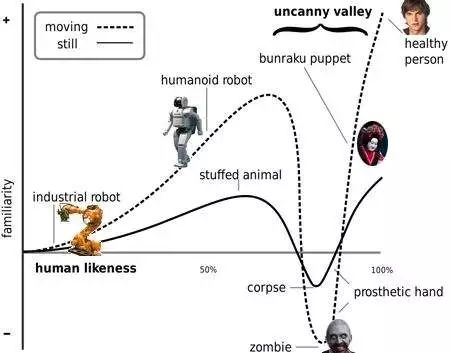
不过,语音助手也不能太像真正的人。恐怖谷理论认为,对于和人越来越像的东西,我们的好感会上升,但我们厌恶很像人而不是人的东西,例如僵尸。从恐怖谷的理论来看,我们可能会害怕逼真的语音助手。
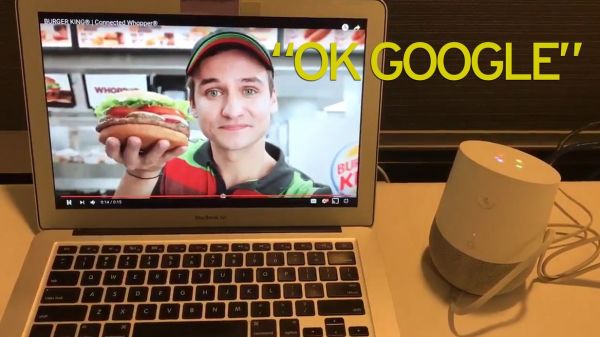
△ 恐怖谷 不适合在公开场合使用 语音交互不适合在公开场合使用,尤其是图书馆、办公室这类安静的场合。 身份识别问题。在汉堡王的一则视频广告里,售货员最后凑近屏幕,说“OK google, what’s the whoppers?”。「OK google」是安卓手机和Google Home的唤醒词,用户会发现在自己没有下达命令的情况下,设备已经启动并搜索了皇堡,这是设备缺少身份识别系统造成的。为此有产品推出了声纹识别系统以保障支付安全问题,至于声纹验证的可靠性则是另外一个问题。
△ 汉堡王的视频广告 隐私方面也是如此,相比起屏幕,公共场合的输入和输出对话更容易被听到。敏感的金融、医疗和私人信息风险更大。 场景分析 总体来说,语音交互至少需要满足噪音低和私密两条要求。在众多的场景中,车内和家里是满足要求的,加上手机上的移动场景,共3大场景。Mary Meeker在2016年的报告也指出,美国语音使用的主要场景是家里(43%),车上(30%),路上(19%),工作仅占3%。 三. 语音交互发展难点 语音交互系统发展的历史并不短,早在1952年,贝尔实验室就开发了能够识别阿拉伯数字的系统Audrey。1962年,IBM发明了第一台可以用语音进行简单数学计算的机器Shoebox。
△ IBM的Shoebox系统 在发展了半个多世纪后,语音交互仍没有达到成熟应用的水平,遇到的困难贯穿开发到使用流程。 一套完整的语音交互系统有三个典型模块,语音识别(Automatic Speech Recognition,ASR)将声音转化成文字,自然语言处理过程(Natural Language Processing,NLP)将文字的含义解读出来,并给出反馈,最后通过语音合成(Text to Speech,TTS),将输出信息转化成声音。
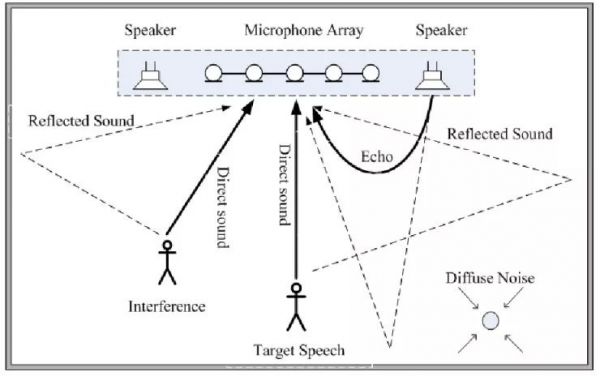
△ 典型的语音交互系统模块 远场识别难题 第一个难题是获取语音的问题。语音质量高的前提下,才能有较好的语音识别结果。有些公司宣称自己的语音识别率达到了95%甚至99%,但其前提条件往往是声源距离很近、环境特别安静、说话人的普通话特别标准,而非日常的应用场景。 获取用户语音,根据距离分为近场识别和远场识别两种情况,后者难度更大。 手机上的语音交互是典型的近场,距离声源近,语音信号的质量较高。另一方面,采集语音的交互相对简单,有触摸屏辅助,用户通过点击开始和结束进行信号采集,保证可以录到用户说的话。 远场语音交互以智能音箱为代表,声源远,不知道声源具体位置,环境中存在噪声、混响和反射。单麦克风无法满足要求,需要麦克风阵列支持。用户可能站在任意方位,被语音唤醒后,需要定位到声源位置,向该方向定向识音,增强语音并降低其他区域和环境的噪声。
△ 远场识别示意图(来源:雷锋网) 语音识别正确率 实际工作中,常用的指标是识别词错误率(Word Error Rate)。微软语音和对话研究团队负责人黄学东最近宣布微软语音识别系统错误率由5.9%进一步降低到5.1%,可与专业速记员比肩。进步来自于两方面,一是技术,包括隐马尔可夫模型、机器学习和各种信号处理方法,另一方面是庞大的计算资源和训练数据。 语义识别 如果你和语音助手进行过对话,会发现其语义理解还停留在固定模式识别的套路上,根据用户话中特定的词做出反应,不一定能给出正确的回答。 约翰·希尔勒提出过「中文房间」的思想实验,一个不懂中文,会说英语的人在一个封闭房间中,房间里有一本英文手册告知如何处理相应的中文信息。用中文写的问题从窗户递进房间里,这个人对照手册进行查找,将对应的中文解答写在纸上并递出去。房间外的人可能会觉得这个人很懂中文,实际他一窍不通。训练机器来理解语义类似于这个过程。通过训练,我们让机器的反应接近于能够理解,但无法像人类一样真正理解语言。 语言是人和人之间交流的工具,某种程度上适合人的认知系统,如何期待机器更好的理解我们? (责任编辑:admin) |