|
月活用户越高的互联网产品,被黑产盯上的可能性就越大。在微信的安全生态里,正是有网络黑产的层出不穷,变化多端,才有了微信安全的不断进化。本文将带你一窥究竟,微信是怎么做异常检测框架的?
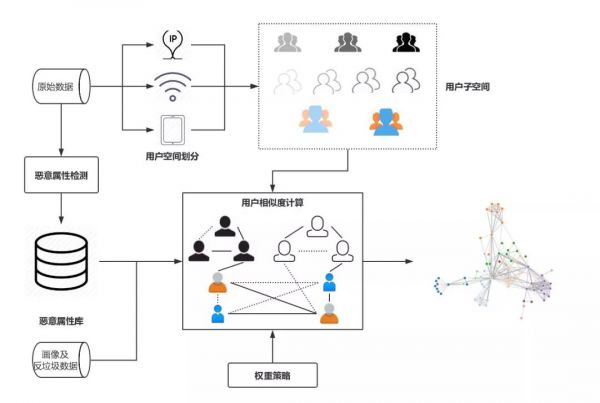
如何在大规模数据下检测异常用户一直是学术界和工业界研究的重点,而在微信安全的实际生态中: 一方面,黑产作恶手段多变,为了捕捉黑产多变的恶意模式,若采用有监督的方法模型可能需要频繁更新,维护成本较高; 另一方面,通过对恶意帐号进行分析,我们发现恶意用户往往呈现一定的“聚集性”特征,因此这里需要更多地依赖无监督或半监督的手段对恶意用户进行检测。 然而,微信每日活跃帐号数基本在亿级别,如何在有限的计算资源下从亿级别帐号中找出可疑帐号给聚类方案的设计带来了不小的挑战,而本文则是为了解决这一问题的一个小小的尝试。 异常检测框架设计目标及核心思路 设计目标为了满足在实际场景检测异常用户的要求,在设计初期,我们提出如下设计目标: 主要用于检测恶意帐号可能存在的环境聚集和属性聚集; 方案需要易于融合现有画像信息等其他辅助信息; 方案需要具有较强的可扩展性,可直接用于亿级别用户基数下的异常检测。 核心思路通常基于聚类的异常用户检测思路是根据用户特征计算节点之间的相似度,并基于节点间相似度构建节点相似度连接图,接着在得到的图上做聚类,以发现恶意群体。 然而,简单的分析就会发现上述方案在实际应用场景下并不现实,若要对亿级别用户两两间计算相似度,其时间复杂度和空间消耗基本上是不可接受的。 为了解决这一问题,可将整个用户空间划分为若干子空间,子空间内用户相似度较高,而子空间之间用户之间的相似度则较低,这样我们就只需要在每个用户子空间上计算节点相似度,避免相似度较低的节点对之间的相似度计算 (这些边对最终聚类结果影响较低),这样就能大大地降低计算所需的时间和空间开销。 基于这一想法,同时考虑到恶意用户自然形成的环境聚集和属性聚集,我们可以根据环境以及用户属性对整个用户空间进行划分,只在这些子空间上计算节点之间的相似度,并基于得到的用户相似度图挖掘恶意用户群体。 此外,直观上来分析,如果两个用户聚集的维度越“可疑”,则该维度对恶意聚集的贡献度应该越高,例如,如果两个用户同在一个“可疑”的 IP 下,相比一个正常的 IP 而言,他们之间存在恶意聚集的可能性更高。基于这一直觉,为了在每个用户子空间内计算用户对之间的相似度,可根据用户聚集维度的可疑度给每个维度赋予不同的权值,使用所有聚集维度的权值的加权和作为用户间的相似度度量。 注:依据上述思路,需要在属性划分后的子空间计算两两用户之间的相似度,然而实际数据中特定属性值下的子空间会非常大,出于计算时间和空间开销的考虑,实际实现上我们会将特别大的 group 按照一定大小 (如 5000)进行拆分,在拆分后的子空间计算节点相似度。(实际实验结果表明这种近似并不会对结果造成较大影响) 异常检测框架设计方案 基于上述思路,异常检测方案需要解决如下几个问题: 如何根据用户特征 / 使用怎样的特征将整个用户空间划分为若干子空间? 如何衡量用户特征是否“可疑”? 如何根据构建得到的用户相似度关系图找出异常用户群体? 为了解决以上三个问题,经过多轮的实验和迭代,我们形成了一个较为通用的异常检测方案,具体异常检测方案框架图如图 1 所示:
图 1 异常用户检测框架 如图 1 所示,首先,用户空间划分模块根据“划分属性”将整个用户空间划分为若干子空间,后续节点间相似度的计算均在这些子空间内部进行;恶意属性检测模块则根据输入数据自动自适应地识别用户特征中的“可疑”值;用户空间划分和恶意属性检测完成后,在每个用户子空间上,用户相似度计算模块基于恶意属性检测得到的恶意属性库和相应的权重策略计算用户之间两两之间的相似度,对于每个特征以及其对应的不同的可疑程度,权重策略模块会为其分配相应的权重值,用户间边的权重即为节点所有聚集项权重的加权和,为了避免建边可能带来的巨大空间开销,方案仅会保留权值大于一定阈值的边;得到上一步构建得到的用户相似度关系图后,可使用常用的图聚类算法进行聚类,得到可疑的恶意用户群体。 用户空间划分 (责任编辑:admin) |