|
用户空间划分阶段我们需要将整个用户空间根据划分属性划分为若干个子区间,实际实验时我们发现在亿级别数据下,使用两阶段聚合,也会出现特定 key 下的数据量特别大的情况,导致 Spark 频繁 GC,程序运行速度极其缓慢,甚至根本无法得到聚合后的结果。 为了解决这一问题,注意到通过划分属性进行划分后,仍然会将特别大的 group 按照一定大小进行切割,那么直接在聚合过程中融合这一步骤不就可以了么,这样就能解决特定属性值下数据特别多的情形,也能极大地提升算法运行效率。 三阶段自适应聚合分为以下四个阶段: 随机局部聚合:设定一个较大的数(如 100),参照两阶段聚合第一阶段操作给每个 key 打上一个随机数,对打上随机数后的 key 进行聚合操作; 自适应局部聚合:经过随机局部聚合后,可获取每个随机 key 下的记录条数,通过单个随机 key 下的记录条数,我们可以对原 key 下的数据条数进行估算,并自适应地调整第二次局部聚合时每个原始 key 使用的随机数值; 第二轮随机局部聚合;根据自适应计算得到的随机数继续给每个 key 打上随机数,注意此时不同 key 使用的随机数值可能是不同的,并对打上随机数后的 key 进行第二轮局部聚合; 全局聚合:经过第二轮随机局部聚合后,若特定 key 下记录数超过设定阈值 (如 5000),则保留该结果,不再进行该阶段全局聚合;否则,则将随机 key 还原为原始 key 值,进行最后一阶段的全局聚合。 Faster, Faster, Faster 经过以上调优后,程序运行速度大致提升了 10 倍左右。然而,在实验中我们发现当对亿级别用户进行相似度计算并将边按阈值过滤后,得到的边数仍然在百亿级别,占用内存空间超过 2T。那么我们有没有可能减小这一内存占用呢?答案是肯定的。 通过对整个异常用户检测流程进行细致的分析,我们发现我们并不需要对子空间内所有用户对进行相似度计算,通过前期实验我们发现当用户可疑度超过 0.7 时,基本就可以判定该用户是恶意用户。根据用户可疑度计算公式反推,当节点关联边的权重超过 18.2 时,其在最后结果中的权值就会超过 0.7,基于这一想法,我们引入了动态 Dropping 策略。 动态 Dropping 策略 引入 HashMap 保存当前子空间每个节点的累计权重值,初始化为 0.0;按照原始算法依次遍历子空间下的节点对,若节点对两个节点累计权重值均超过阈值(18.2),则跳过该节点对权值计算,否则则根据原始算法计算节点对权重,并累加到 HashMap 中,更新关联节点的累积权重值。 引入动态 Dropping 策略后,对于较大的用户子空间,程序会跳过超过 90% 的节点对的相似度计算,极大地减少了计算量;同时,亿级别用户相似度计算生成的边的内存占用从原来超过 2T 降到 50G 左右,也极大地降低了程序所需内存占用。 图划分策略 通过相似度计算得到的用户相似度关系图节点分布是极不均匀的,大部分节点度数较小,少部分节点度数较大,对于这种分布存在严重倾斜的网络图,图划分策略的选择对图算法性能具有极大影响。为了解决这一问题,我们使用 EuroSys 2015 Best Paper 提出的图划分算法 HybridCut 对用户相似度关系图进行划分。
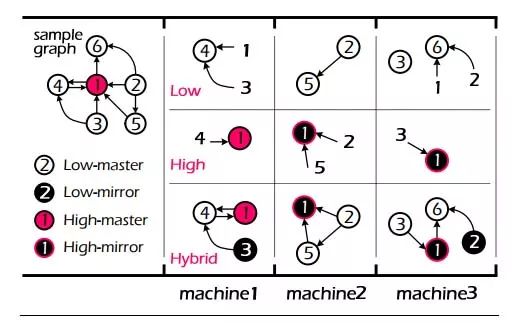
图 4 HybridCut 图划分算法 如图 4 所示,HybridCut 图划分算法根据节点度数的不同选取差异化的处理策略,对于度数较低的节点,如节点 2,3,4,5,6,为了保证局部性,算法会将其集中放置在一起,而对于度数较高的节点,如 1,为了充分利用图计算框架并行计算的能力,算法会将其对应的边摊放到各个机器上。 通过按节点度数对节点进行差异化的处理,HybridCut 算法在局部性和算法并行性上达到了较好的均衡。以上仅对 HybridCut 算法基本思路进行粗略的介绍,更多算法细节请参阅论文 PowerLyra: Differentiated Graph Computation and Partitioning on Skewed Graphs。 总结和讨论 优点与不足 优点 上述异常用户检测框架具有如下优点: 能够较好地检测恶意用户可能存在的环境聚集和属性聚集,且具有较高的准确率和覆盖率; 能够自然地融合画像信息以及反垃圾信息,通过融合不同粒度的信息,可提高算法的覆盖率,同时也给算法提供了更大的设计空间,可以按需选择使用的特征或信息; 良好的扩展性,可直接扩展到亿级别用户进行恶意用户检测,且算法具有较高的运行效率。 不足 (责任编辑:admin) |