|
为了进行节点间相似度的计算,首先需要将整个用户空间划分到不同的子空间中去,那么这些用于划分的属性该如何选取呢?经过一系列的实验和分析,我们将用户特征划分为以下两类: 核心特征:核心特征指黑产帐号若要避免聚集,需要付出较大的成本的特征,主要包括一些环境特征; 支撑特征:支撑特征指黑产帐号若要避免聚集,改变所需成本较小的特征。 不难发现,对于上述核心特征,黑产规避的成本较大,所以在具体的划分属性的选取上,我们使用核心特征对用户空间进行划分,并在划分得到的子空间上计算节点对之间的相似度。在子空间上计算节点之间的相似度时,我们引入支撑特征进行补充,使用核心特征和支撑特征同时计算用户之间的相似度,以提高恶意判断的准确率和覆盖率。 何为“可疑” 可疑属性提取 在确定划分属性后,一个更为重要的问题是如何确定哪些用户属性值是可疑的?这里我们主要对用户脱敏后的登录环境信息进行分析,依赖微信安全中心积累多年的环境画像数据,通过对用户属性值的出现频次、分布等维度进行分析,提取出一些可疑的属性值。 多粒度的可疑属性识别 在进行养号识别的实验过程中,我们发现,单纯依靠若干天登录数据的局部信息进行养号检测往往无法达到较高的覆盖率。为了解决这一问题,在可疑属性提取过程中,我们会融合安全中心现有的环境画像信息以及反垃圾数据等全局信息辅助进行判断,局部信息和全局信息的融合有以下两个好处: 融合局部信息和全局信息,可增大可疑属性判断的置信度和覆盖度,提高算法覆盖率; 增加了用户相似度计算设计上的灵活度,如若特定帐号与已封号帐号有边相连,可通过赋予该边额外的权重来加大对已知恶意用户同环境帐号的打击。 恶意用户识别
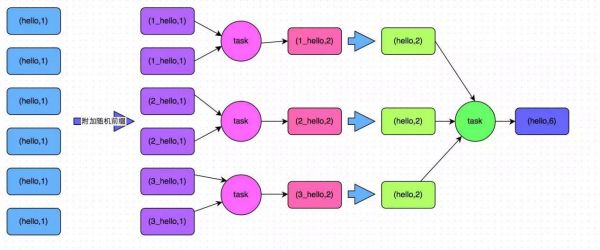
我们将超过一定阈值的用户视为恶意用户,其中,阈值可根据不同阈值得到的算法的准确率和覆盖率选取一个合适的阈值。 另,处于性能和可扩展考虑,我们使用 Connected Components 算法来识别可疑的用户团体,同时,得到恶意团体后我们会对团体进行分析,提取在团体维度存在聚集性的属性值,以增强模型的可解释性。 从百万到亿——异常检测框架性能优化之路 初步实验时,我们随机抽取了百万左右的用户进行实验,为了将所提方案扩展到全量亿级别用户上,挖掘可疑的用户群体,我们做了如下优化: Spark 性能优化 在基于 Spark 框架实现上述异常检测框架的过程中,我们也碰到了 Spark 大数据处理中常见的问题 —— 数据倾斜。分析上述异常检测方案不难发现,方案实现中会涉及大量的 groupByKey,aggregateByKey,reduceByKey 等聚合操作,为了规避聚合操作中数据倾斜对 Spark 性能的影响,实际实现中我们主要引入了以下两个策略:两阶段聚合和三阶段自适应聚合。 两阶段聚合 如图 3 所示,两阶段聚合将聚合操作分为两个阶段:局部聚合和全局聚合。第一次是局部聚合,先给每个 key 都打上一个随机数,比如 10 以内的随机数,此时原先一样的 key 就变成不一样的了,比如 (hello, 1) (hello, 1) (hello, 1) (hello, 1) 就会变成 (1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行 reduceByKey 等聚合操作,进行局部聚合,得到局部聚合结果 (1_hello, 2) (2_hello, 2)。然后将各个 key 的前缀给去掉,得到 (hello,2),(hello,2),再次进行全局聚合操作,即可得到最终结果 (hello, 4)。
图 3 两阶段聚合 三阶段自适应聚合 (责任编辑:admin) |