|
首先介绍一下搜索的物理逻辑:用户输入信息,系统根据输入的信息匹配相对应的内容,再按照特有的rank逻辑进行排序展示。这个表述只是简单的介绍,如果想要知道具体的原理,还需要深入到搜索词库的建立。每个搜索系统都有一个词库和一个索引库,他们之间是可以进行快速的关联匹配的,词库就好比一本书,索引库就好比目录,当你心里有具体想翻阅的某个内容时,就可以根据目录找到页码,匹配到相关内容。实际上「查书」这样的动作就已经构成一个简单的搜索过程了。那么,机器检索复杂在哪里?这边要介绍一个新的概念:分词。
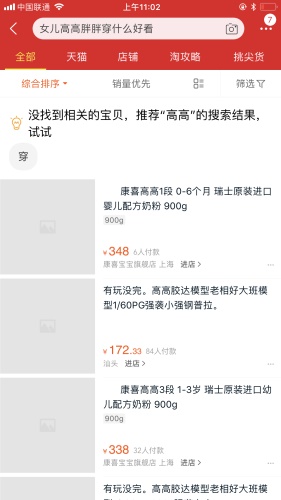
给大家看个幽默图片轻松一下,这位老母亲也是为自己的崽崽操碎了心。在图片中,用户输入检索内容时,你会发现,这个文本结构非常的口语化,「女儿高高胖胖穿什么好看」这更像是一个问句,很明显用户对于内容没有明确的预期。如果用这样口语化的描述性文本在淘宝中进行搜索,会出现什么样的结果呢?结果将会是没有匹配。
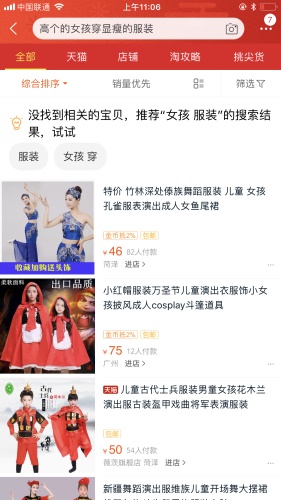
既然这样搜不到,那我们换个思路来吧,「女儿高高胖胖穿什么好看」,是不是可以换成「高个的女孩穿显瘦服装」这样的文本进行检索呢?我们来试试看。
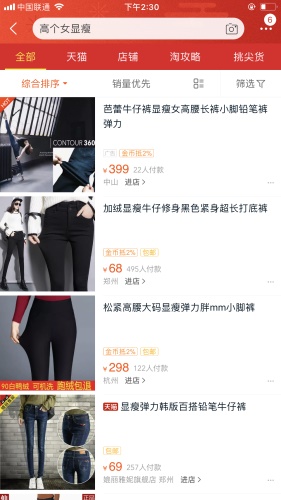
咦,还是没有,那我们干脆再简化字段扩大搜索范围吧,换成「高个女显瘦」来搜索呢?
结果匹配到了很多漂亮时尚的衣服,搜索完成。 回头再梳理一遍过程,我们从「女儿高高胖胖穿什么好看」这样的非结构化文本到「高个的女孩穿显瘦服装」再到「高个女显瘦」的简化过程,就是一次人工分词操作。如果在足够智能的搜索引擎上,这些都可以自动完成。分词,简单表述为:拆分滤用字符串。例如,三国的军事家司马懿。可以拆分为「三国」、「的」、「军事家」、「司马懿」这些词组。那在分词系统中,「的」、「是」、「在」是常见的停用词,通常会被直接pass掉,词组进一步拆分为「三国」、「军事家」、「司马懿」。经过这样的处理,非结构化的内容就会转化成结构化的,可匹配度高的词库,可以轻易的匹配到想了解的内容。说了 这么多搜索原理,那优化思路在哪呢?这里说两点自己的看法。 词条归一 这是针对词库的优化,说到这个,得介绍一下搜索系统匹配关键词的规则「TF-IDF算法」。假如用户在百度上搜索「苹果」,那苹果有很多相关的信息文档,怎么才能准确匹配呢?系统需要提取这些信息文档的关键词,感兴趣的小伙伴可以百度公式。系统计算出文档里每个词的TF-IDF值后,然后按降序排列,取排在最前面的几个词与搜索词匹配就可以得到准确的匹配结果,不会出现我搜的是苹果,出来的是青苹果乐园。进一步的还有Lucene的打分系统,让好的,召回率高的内容优先展示。说了这么多,词条归一到底是什么?其实就是将同一词义的词组归为同一个词,比如苹果的别称有「蔷薇科苹果属果实」、「柰」、「滔婆」、「apple」、「りんごちゃん」等等,这些词组说的都是同一个意思,所以词条归一就是将这些词组归为同一类别,扩大匹配范围,提高关键词召回率。 更符合业务目标的rank逻辑 我们在搜索完成后,会看到搜索结果会按照特定的顺序排序,再进行展示。有些产品中,展示的顺序是否能够切合业务目标,会直接影响到产品的收益。所以,制定展示逻辑的算法要高度理解业务内容,实时回归业务进行规则的更新。 (责任编辑:admin) |