|
对于跨端产品,有些设计师会集中精力关注 C 端的设计,而对 B 端的内容配置部分则比较轻视。而当 C 端用户看到配置得乱七八糟的内容时,却不会觉得这是 B 端用户的锅,只会吐槽产品设计本身不合理,作为跨端产品设计师,应该为完整的全链路体验负责。
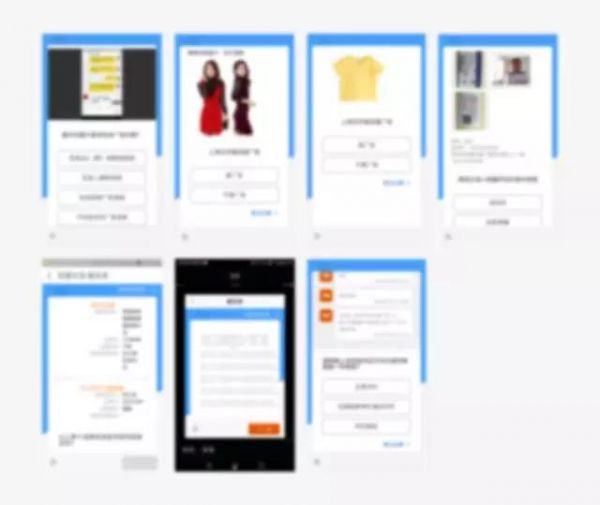
对于很多内容型产品,C 端用户见到的界面里,有相当一部分并非直接出自设计师之手,而是 B 端的商家、运营们配置的结果,而如果没有对 B 端用户的内容配置进行合理的规范约束、引导和审核,让其自由发挥的话,最终在 C 端的呈现效果将完全不可控,影响到产品的整体视觉印象和使用体验。 我目前负责的一块业务在这方面就存在比较严重的遗留问题,这个业务的主要模式是商家和运营在 B 端发布带薪任务,C 端用户申领和完成任务来赚取薪酬。而业务的 B 端任务配置等环节目前几乎没有任何约束可言,比如信息展示区域,B 端用户随便找个第三方编辑器写好 HTML 内容再往配置表单里一扔,就直接呈现给了 C 端用户,于是各种千奇百怪的字号、配色、对齐等问题纷纷出现。除了 C 端的展示效果失控以外,B 端编辑的代码门槛(需要一定HTML和JSON基础)、大量数据重复编辑成题目的低效等问题,对 B 端用户本身也很不友好,影响到 B 端未来向更多外部商家开放的可行性。 在这样的问题背景下,我们在重新设计 B 端整体的任务发布流程时,对其中任务配置(包括信息展示与题目)这个关键一环进行了重点优化,基于组件化的设计思路,完整走查已有和潜在的业务用例,从中抽象出适用于各种业务场景、可灵活拼装组合的可视化组件/模块,并约束好最终映射到 C 端的样式规范,达到降低 B 端配置门槛和规范 C 端呈现效果的两大设计目标。因为业务场景很多、横跨 PC/移动两个平台,涉及到的背后逻辑也很复杂,在适配业务场景时还要考虑到兼容性、技术可行性等,设计经历了一波三折的碰撞才接近定稿,以下就具体讲讲我对内容配置场景下的进行组件化设计过程中遇到的挑战和思考。 完整用例走查与分层抽象归纳 复杂多元的业务场景是对于组件化设计较大的挑战之一,为此我们花了一段时间体验 C 端各种类型的线上任务、收集用户反馈截图等,并在前端和运营的帮助下整理出了相对完整的用例列表,除此之外也结合和业务方了解到的后期扩展计划,将还未开发上线的潜在新业务场景纳入一并考虑。这个过程会耗费一定时间,但却是组件化设计前期非常必要的步骤,直接影响到组件的覆盖面和可扩展性。
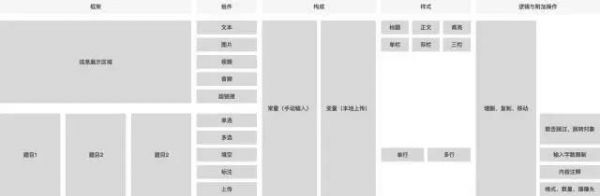
在业务用例收集到一定程度后,开始对内容维度自上而下分层进行归纳,抽象出各类展示/题目组件,和不同组件的构成、样式与附加逻辑(有点类似HTML、CSS和JS的关系),对信息结构逐渐形成清晰的理解。
在不同维度的内容层级梳理清楚后,便基于此搭建 B 端配置页面的布局框架,这个过程让配置步骤从毫无重点优先级(比如在一个表单里同时混杂了构成、样式与逻辑相关的配置项,低频的逻辑配置操作出现在前置显眼位置)变为自上而下层层递进(激活框架-添加组件-插入构成元素-更改样式-设置附加逻辑),关联信息配置的联动映射关系也更清楚。 基于梳理出来的组件样式类型与逻辑配置项,又可以进一步定义映射到 C 端组件的视觉与交互规范,而 B 端用户只能基于规范已有的内容进行有限的选择(比如定义某段文本属于「标题样式」还是「正文样式」),不能随心所欲地自定义控制样式(如随意更改文本的字号、颜色)等。 大量级数据的编辑效率提升 前面梳理内容层级时,构成部分我拆成了常量(手动输入的数据)和变量(本地上传的数据),而变量这个概念的引入则和大量级(1K+、1W+)数据导入的业务场景紧密相关。 举个例子,如果 1 个 B 端用户想通过任务发放收集 1000 条不同文本的语音朗读数据,如果没有变量(本地上传的数据)的概念,就意味着他需要手动选择或复制 1000 次文本朗读组件,而每次更改的只有朗读对象这一个字段。但如果选择从本地导入这 1000 条文本的表格数据并统一命名为变量 text,编辑朗读对象时插入这个叫 text 的变量,则只需要编辑 1 次文本朗读组件就够了,系统会根据变量值的个数自动生成 1000 个任务发放给 C 端用户,大大提升了任务配置效率。 (责任编辑:admin) |